Machine Learning is learning from data and identifying the trend, pattern and insights from data in hand. It is gaining very fast popularity across the industry sectors. Machine Learning skill is an essential one nowadays to analyze a large amount of data to come up with some robust model thus enabling quick decision making and policy optimization.
Measures in Power BI are really a beautiful feature. They are fast in the calculation, has the benefit of reusability. Measures can be applied to multiple tables. We create measures to obtain counts, averages, sums, ranking, percentiles, aggregating year to dates and many more handy calculations.
Measures are dynamically calculated. And most importantly it gets imported in other applications like MS Excel through its report format. A good data modelling and creating useful measures are among the core skills Power BI Pro users have.
So, in nutshell, measures in Power BI are one of the most important features you must know and use. In this article, I am going to discuss how to use them with a simple application using real-world data.
I would suggest going through this article for in-depth knowledge of Power BI measures. It is from the creator Microsoft itself. This article will give you the overview and the necessary idea about measures to apply the steps described here.
NB: Being a non-native English speaker, I always take extra care to proofread my articles with Grammarly. It is the best grammar and spellchecker available online. Read here my review of using Grammarly for more than two years.
The data set used here is the same used to demonstrate the data modelling process in Power BI. For the first time readers, a brief description of the data is given below.
The data I used here is crop production data of different states of India. This data is accessible at Data.world. This is real-world data and without any garbage.
The columns are
“State_Name” containing different states of India.
“District_Name” containing state-wise different districts name
“Crop_Year” has the year of production
“Season” has the particular season of crop production
“Crop” is the particular crop name
“Area_ha” this column contains a total area of under the crop in Hectare
“Production_tonnes” has a total production of the season in Tonnes
Use of DAX (Data Analysis Expressions) to create Measures
We use Data Analysis Expressions (DAX) in Power BI to create measures. The same DAX is used for Excel formulas. The only difference is, in Excel, DAX is applied on cells and columns whereas, in Power BI, DAX is applied on tables and columns of the data model. And they are very fast in calculations.
Implicit and explicit measures: which one you should use?
Measures are of two kind one is implicit measures which gets calculated by default and the other one is explicit measure. Now both of these measures yield the same result.
But there are subtle differences between the calculation approaches of these two. Which you should know and use accordingly.
Implicit measures are easy to calculate and you need not write any DAX expressions for it. But it has its own share of disadvantages. Which is Implicit measures are not reusable.
On the other hand, explicit measures require some knowledge of writing DAX expressions to achieve desires result. But they can be reused. Also, you can make little changes in the DAX expression you wrote to use it for other calculations.
An example of limitations of Implicit Measures is its inability to handle division by 0(zero). If there are some calculations have divisions and your data contains some zeros in the numerator, then Implicit Measures will give garbage values.
But such a situation is well handled by Explicit Measures. Where these measures through a tiny error displaying “NAN” i.e. “Not A Number”. In this way, you can understand the possible problem and can correct it.
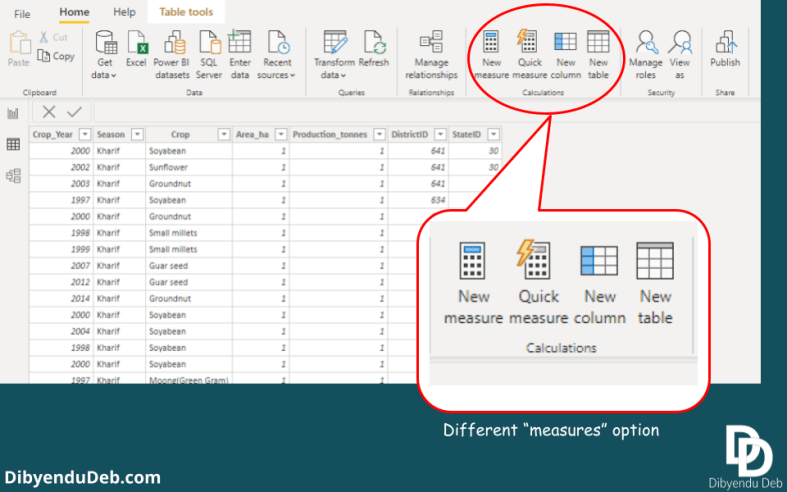
New Measure and Quick Measure
These two are another options provided by Power BI when you need to create measures. Now again, creating a Quick Measure is easy and does not require writing DAX expressions.
Where creating New Measure needs writing few lines of DAX expressions. But it has some advantages over Quick Measures. I will discuss it with example here in a bit.
The figure below displays the options for creating “New measure”, “Quick measure”, “New column” and “New table”.
Different measures option in Power BI
While in case of “Quick measure” a wizard opens which help us to define the calculation. Again it is easy as we don’t have to bother about writing DAX at the cost of losing the flexibility and reusability offered by it.
Common mistake while creating new measure
Here I would like to mention a very common mistake while you are in the process of creating you first ever New measure. It may sound silly but related to very basic concept of measure in Power BI.
The role of a measure in Power BI is to apply some aggregate functions of the column values in the report. So, it is important to remember that measures can not be created using single row values.
See the error thrown by Power BI in the below figure when I have tried to create a new measure using single row values. My intention was to calculate productivity by dividing crop production with the area.
Common mistake while creating measures for the first time
And the error clearly directed me that a “single value” can not be determined. We need to create “New column” for that purpose.
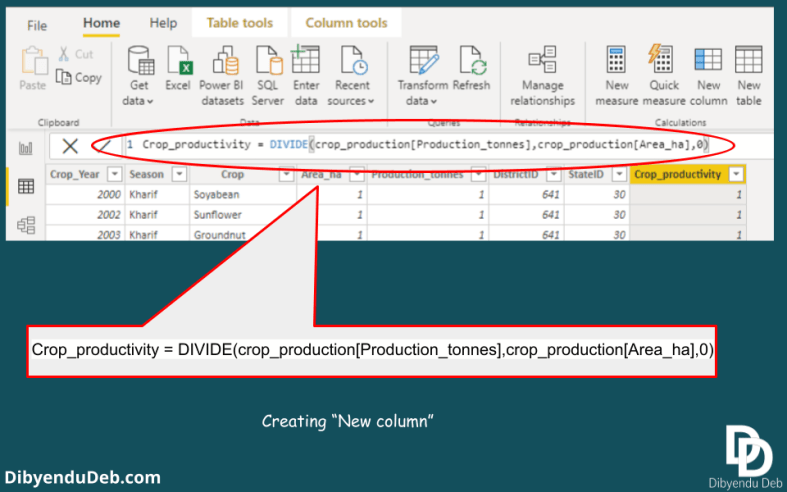
Creating a “New column”
For creating a column to calculate the productivity from the crop production and area values, we will create a “New column” here. Simply click the “New column” option. A formula bar will appear where we need to write the DAX for the calculation.
Creating “New column”
Now see in the below figure where the DAX has been written for crop productivity calculation. Important to note that I have mentioned an alternate value as 0 at the end of the expression. It avoids the problem that arises whiling dividing by 0.
Creating new column with crop productivity
Creating “New measure”: an Explicit measure
While we create new measure by clicking the “New measure” option, a formula bar appears in the window. See the below figure. The “Fields” pane at the right also starts to display the Measure with a calculator icon. By default, a new measure has the name “Measure”.
Creating a “New measure”
Now we have written a DAX for calculating the average crop production. Its very simple and remember selecting the relevant table while writing the DAX. It will help you select the right column by prompting from the selected table columns.
Creating a new measure
As I have already said that explicit measures are reusable, it means that one explicit measure can be used to create another explicit measure.
Application of an Explicit measure
Use of explicit measure
Implicit measures
Here we will see how a measure can be created implicitly. It is an easier option compare to explicit measures. But it is always advisable to go for an explicit measure for its several advantages as I have discussed before.
In the below figure you can see that a bar plot has been created for the Area_ha column. By default it is the sum which is selected. You can change to other options as available in the figure.
And all these options create an implicit measure for each of them. You will not get them in the field options there. Which means that implicit measures are not reusable. Every time you want to do the same calculation, you have to go through the same process.
Creating an implicit measure
The bar plot takes only the measure “Area_ha” which gives the sum of all the cropped area from all the states. So, it gives a single bar for a single value. You can drill down further to any level adding them as values.
Like in the below image we can see that the cropped area has been displayed district wise.
Application of implicit measure
Final words
In this article, we have mainly focused on creating measures both implicit and explicit. Both measures have been shown using practical examples.
As I have discussed the merits and demerits of both the measures, it is prudent that creating explicit measures always has the edge. Implicit measures are easy to apply. That’s why any new Power BI users always prone to use the implicit measures.
Although in the long run, when he delves into more advanced use of Power BI, the data size and complexity increases, he finds that using implicit measures are not helpful in terms of their reusability.
Also, as the Explicit measures get dynamically calculated, it puts less burden on the computer memory and quick to give result.
Hope this article will help you to get a good grip and understanding on the use of measures. If you have any queries or issues regarding application of measures let me know through comments below.
I would like to address them which will enrich my knowledge too.
Data model relationships are the core of Power BI. The report preparation and visualization becomes very easy if data modelling is done well. So here in this article, we will discuss data modelling relationship with a simple example.
A common misconception among Power BI users is that Power BI is all about visualization. But that is not the case. Visualization is only the icing on the cake. Whereas the data modeling part is the cake itself.
You should give 75% of your time in data transformation and modeling. For data visualization rest 25% is enough. A good data model will enable you to dig into the data insight and to know the relationship between all the variables.
You can get a good detailed discussion on data modeling in Power BI here. The document is prepared by Microsoft itself. So no point to discuss the same thing here again. My target will be here to present you a small practical example of data modeling.
Use of multiple narrow tables
I will encourage you to use multiple narrow tables instead of a big flat table with several columns. And here lies the beauty of data modeling and relationships. Power BI can work with big wide table. But it is a kind of constrain while scaling the model.
With time your project is going to increase in size. The tables will increase in rows. Chances are there that table number will also increase as well as the complexity of your model. Fetching required information from a big table with lots of columns is time-consuming. It occupies a good amount of computer memory too.
In this scenario use of multiple tables with few columns can make your life easier.
Data model relationships in Power BI: from the Business Intelligence point of view
Business Intelligence or BI is of very critical importance in industries. Almost all businesses have a well-developed database to store all kind of transactions. Over time such databases get huge and extracting information becomes complex.
Extracting information from such big data requires experts in the field. Business houses appoint software developers to extract data, transform and load in a well-maintained data warehouse.
Creating a data warehouse is essential because no industry wants to disturb its always busy database. It may lead to jeopardies the real-time data transaction process. That’s why software developers keep their required information in a data warehouse of their own.
Now for a person without software development background it is tough to handle a data warehouse. Here comes the power of Power BI. It makes the whole ETL (Extraction, Transform and Load) process of data a cake walk for anyone with zero knowledge in software development.
A practical example of data model relationships in Power BI
Here is a simple example of how you can model relationships in Power BI. The data I used here is crop production data of different states of India. This data is accessible at Data.world. This is a real world data and without any garbage.
Data world already has provided the data in a refined manner. So, very little left for us on the part of data cleaning. And we can straight way jump into the modeling process.
Below is a glimpse of the data file imported into Power BI. This is the screenshot of the data transformation window of Power BI.
Glimpse of the crop production data
The columns are
“State_Name” containing different states of India.
“District_Name” containing state-wise different districts name
“Crop_Year” has the year of production
“Season” has the particular season of crop production
“Crop” is the particular crop name
“Area_ha” this column contains a total area of under the crop in Hectare
“Production_tonnes” has a total production of the season in Tonnes
Now this is not a very big table. Still we can reduce its size and create a custom key to further improve the data model.
Creating a custom key
Using a column to create a custom key needs selecting a variable to create a separate table. Let’s select the “District_Name” to create a new table.
Now, why should I select this column? the answer is easy this column has some redundant values. The same way the “State_Name” also does not have unique values so either of them can be selected.
We will create a separate table with this column where they will be unique with a far lesser number of rows. In this way, these tables will help us data munging, data wrangling and whatever fancy term you want to use 🙂
Trimming the column
The first step is to trim the column to remove any unwanted white spaces from the column. Just select the column in question, right-click and select transform to get the trimming option. See the below image.
Trimming the column
Removing the blank values
The second most important step is to replace any blank values. Blank values are a real problem in data analytics. Blank values can lead to spurious result as tools generally not capable to handle them. So, we should filter them out carefully in data transformation stage itself.
We can easily inspect the column quality and distribution from the view tab as shown in the below image.
Checking column quality and distribution from the view tab
So we can conclude that this particular variable is already free from any white space. See that data quality option shows “Empty as 0%”
But if your data has blank values then it is a convenient option to check it. For example, if we check the “Crop_production” variable we can see that the empty as <1%. That means it has some blank rows.
Checking for rows with “null” values
To check for the blank values we need to click the filter icon at the left of the column name. Uncheck the “Select All” option and check only the null values as shown in the above figure. Now Empty fields are 100%.
Replacing null values with 0
In order to replace the null values, you have to right click on the column name and select the “Replace Values…” option. In the new window replace the null with 0 and click OK. Now you can check the Empty has become 0% and all null values have been replaced by 0.
As no other column shows any value as Empty, so we have made our data completely free from any blank values. And we can now proceed for next step.
Creating new query and converting to table
In the next step we will create new query using the “Add as New Query” option. See the below image for the steps you should follow to create new query and then converting to a new separate table.
Creating new query and converting to new table
Removing duplicate entries
The newly created column has several duplicate entries. To make it a table with only unique entries, we need to remove the duplicates. As given in the below image, click the option “Remove Duplicates“. Now you have a column with all different districts of India.
Creating table with “District_Name”
Creating IDs for the column
It is very helpful creating a custom ID for the values in newly created column. Since the IDs are created by you, you have full control over it. Creating ID has a simple option in Power BI. See the following image to understand the steps.
Creating index column
The “Add Column” tab has options for both custom column and default column IDs starting from 0 or1. You can choose any of them. For example, here I have selected column ID starting from 0.
Merging the tables
The next step is to merge queries. As we have completed creating custom keys, now we need to merge the designated tables. See the following images to complete the tasks. Go to the “Home” tab and select “Merge Queries” option.
Selecting merge queries option
Now a “Merge” window will open and you need to verify that both the tables have exact same number of rows match. Here you can see that in both tables we have 246091 number of matching rows.
Merging the tables
Now the newly created column will appear in the table. You can see in the below image that the whole table is displayed as a column. So you need to select the particular column and deselect the option “Use original column as prefix“.
Selecting particular column from merged table
Data model relationships in Power BI: task completed
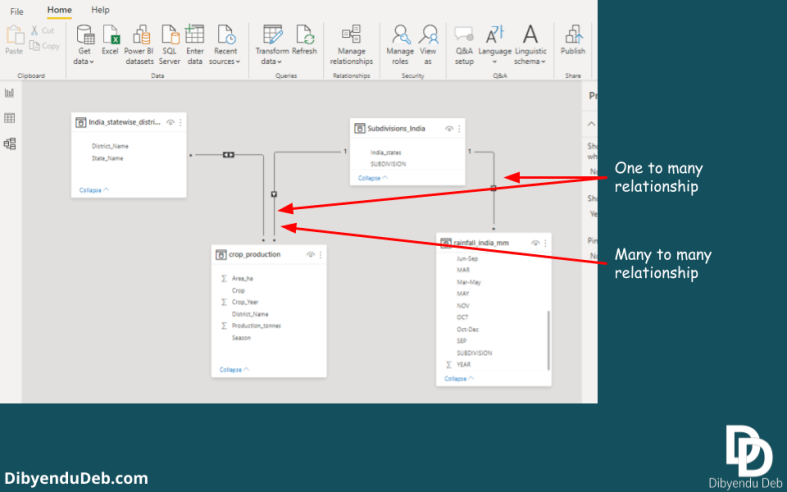
With the last step, we have completed creating a data model relationship between the two tables. You can verify that in the “Model” view of Power BI. It displays a “One to Many” relationship between the tables.
Final data model relationship
Final words
So, here is a simple example of data model relationships in Power BI with practical data. It also displays how can you create custom keys to join or merge into different tables. It is an effective way of creating a relationship as you have full control over the keys.
I hope this article will help you to start with data model relationships in Power BI with ease. In case of any doubt you can comment below. Also suggest if there any interesting topic regarding data modeling you have.
With this article, I am planning to start a series of articles over the Power BI application to solve real-world problems. So, keep visiting the website for new and interesting articles.
Microsoft’s Power BI is a very popular and most frequently used data visualization business intelligence tool. This is an introductory article on Power BI which will be followed by a series of practical problem-solving articles. So it will be “learning by doing”.
Data exploration and visualization is the most basic yet very important step in data analytics. It reveals important information to understand the data and relationships between the variables. Without a thorough understanding of these variables, we can not approach for in-depth analysis of the data.
Although there are programming tools like R and Python which are the most capable of advance data science jobs, using them for data exploration every time is tedious.
They prepare exhaustive analytics on the data with some beautiful, professional-looking charts, interactive dashboard and real-time reports really quickly. Another added advantage is collaboration with your team by publishing the report through their cloud service.
For industry leaders, it does not matter if you have created a report writing a thousand lines of codes or used a tool like Power BI. They need just a good analytics and insights from the data. So, besides tools like Python and R a data analyst should have a working knowledge of these tools too.
But why Microsoft Power BI for data visualization?
See the below figure where the different Analytics and Business Intelligence Platforms are compared with respect to two different parameters. On the X-axis it shows the completeness of vision and on the Y-axis it has the ability to execute. We can see that with respect to both these parameters, Microsoft finds its place at the top.
Analytics and Business Intelligence Platforms comparison
Increasing popularity: Google trends
Microsoft Power BI has a close competitor as Tableau analytical software for Business Intelligence. Tableau has been a popular choice of business houses since long. Compare to Tableau, Power BI came very late for public use.
Tableau made its presence in the field of business intelligence way back in 2004. Whereas Microsoft Power BI was designed by Ron George only 10 years back in 2010 and made available for public download on July,11 of 2011.
Soon after its availability, it rapidly became popular mainly because of its more affordability, user friendly interface and most importantly its compatibility with hugely popular widely used Microsoft office products.
Below is an example (Google trends) how Power BI, since its inception, gradually overtake Tableau in popularity and became the most Google-searched term in business intelligence tool in recent past.
Installation of Power BI for data visualization
I will discuss the free version of Power BI which is Power BI desktop here and you can install it from the Microsoft store itself and the process is well documented here. Just search Power BI in the windows store and click download. It will start downloading a file sized nearly 500 MB.
Below is the screenshot of my computer when the installation was complete and Power BI was ready to launch.
Power BI desktop in Microsoft store
When it is opened for the first time, you will get to see a window like below.
First screen after Power BI gets installed
Just click “get started” and you are ready to work with the Power BI. The first step is to bring the data in Power BI. Here you will get an idea why Power BI is so popular. It has the capacity to load from any kind of data source you can name.
Compatible data sources for Power BI
Power query
Power query is the most powerful feature of Power BI. It helps us clean the messy raw data. In real-world the data, we have to deal is never clean. Sometimes the data is arranged in a fashion which is only human friendly.
A human-friendly data means lots of tags and long strings within the data file for the ease of human understanding. But a machine does not have anything to do with these texts and arrangements. Rather they create problems to get read by a computer.
Power query helps to clean the data and also transform to create desired information with the available data. Below is an image showing how you can create a custom column from the columns available.
Custom column in Power BI
Query editor
So in this data transformation step, we need to convert a human-friendly data to a machine-friendly data. Don’t just click on “Load”, spend some time in data cleaning before loading it. And here comes the most powerful part of Power BI “Query editor”.
In the below image a query editor has been used to modify the data. According to your transform action, the query is built by Power BI by default. The query used the popular “M language”. You can make necessary changes in the query to get the desired result.
The syntax of the query is very easy and in case any problem a quick Google search is always helpful.
Use of query editor
You need to master the use of Power BI query editor in order to dig deep into the analysis. It is a common misconception that Power BI is only about visualization. Many Power BI users directly jump into the visualization without proper data transformation and data modelling.
But it is a wrong practice. Query editor is refered as the “Kitchen” of Power BI. The better you will able to use it the more information you can extract from the data.
Use narrow tables
A good practice for data modelling is to use narrow tables. A wider table will create a problem when you attempt some complex calculations. Always break down a wider table identifying variables which are redundant and place them in a separate table.
Using tables with lesser columns instead of wide tables
As your table size grows with time i.e. number of rows increases. And there are chances that you need to add more tables in data modelling. In both cases narrow tables will help you to create relationships with ease and fetch required data.
Create as many tables as required for analysis. And later link them using primary key and foreign keys. We will discuss this process in a separate article dedicated to data modelling.
Power query is the built-in data tool for both M.S Excel & Power BI. It helps us to transform the data as we wish in order to build a meaningful model between the dimension tables and fact tables.
Star schema: Fact tables & dimension tables
Fact tables and dimension tables are components of dimensional modelling with a star schema.
Power BI for data visualization: Star schema
Fact tables
These tables are generally long tables containing numeric values.
Dimension table
Now dimension tables are those table which generally contains information related to Who, What, Where, When and How about the fact tables. These are short tables compare to fact tables and contains mainly string variables.
Query settings
It is the particular part of Power BI data transformation window where all the magics happen. It automatically keeps track of all the data transformation steps you perform. You can go to any of these steps any time and make any kind of changes you want also replicate them further.
It kind of helps you to time travel to see the changes, how the data was cleaned and what are the data transformation steps.
DAX: Data Analytics Expressions
These are functions and operators available in Power BI which enable us to perform analytical services, building formulas, data modelling and information extraction (source: Microsoft document).
DAX functions are almost 250 in numbers used in different data transformation applications.
Measures Vs calculated columns
Implicit measures
Implicit measures are already defined measures in Power BI.
Explicit measures
These are measures defined by the Power BI user and has many benefits over the implicit measures. Explicit measures give the Power BI user more freedom, reusability and flexible applicability through connected reports.
Measures and calculated columns
Both of these options yield the same result and may appear as with the same functionalities. But it is always a good practice to use Measures over calculated columns for the reusability and flexibility of Measures.
Measures also have a plus side when you want to publish your analytical report with Excel or other applications. If you open any Power BI published file with excel, you can find the Measures you created but not Calculated columns. Hence you can reuse only the Measures not the calculated columns.
Measures make your application more light and memory friendly
Measures are being calculated dynamically and do not consume any space in the file. Hence use of measures instead of calculated columns keeps the Power BI application file very light in size even lighter than an excel file.
Use of Explicit measures also makes your data model execute very fast. You should always keep the scalability factor in mind while building models. Your model should be flexible so that it remains equally efficient with the increasing data size.
Hybrid measures
These measures are to calculate some statistics using variables from different tables. Once such measures are created they become a part of the model and can be used everywhere.
Unpivot columns
This is also a beautiful feature of Power BI. With a click it can make the rows converted to columns and vise versa in a table.
Model & relationship view
As soon as you complete your transformation/editing the data file the files are saved as Power BI files. Power BI by default identifies the relationship between the files and displays them in the Model and relationship view. You can change the model relationship and build your own.
Below is an example of such modelling. A typical star schema consists of one to many relationships from dimension tables to fact tables. In this image, I have one many to many relationship also. But keep in mind you should have a clear idea of why you are creating it.
Data relationship view
This modelling part is so important. An efficient data modelling leads to easy and effecitive data analysis. A basic idea of data warehousing can be helpful here.
Once you are done with data transformation and model building, click “Close and apply” to exit the query editor.
Here we begin…
Power BI is such an interesting and powerful analytical platform and I wish to devote a complete blog category on this. As I am learning it the interest continues to grow.
It may appear overwhelming at first. With more practice, things become easier. Even you will become hungry for a more complex problem with messier data.
This is just starting off learning Power BI and here is only a glimpse of some important features. I will be covering more advanced applications in coming articles. I will update you about different analytical techniques as I learn them.
Let me know how you find this article and which topics you want to be covered in coming blogs by commenting below. Your suggestion will help me to improve the quality of articles as well as to introduce new interesting topics.
This article presents a thorough discussion on how to perform Exploratory Data Analysis (EDA) to extract meaningful insights from a data set. And to do this I am going to use Python programming language and its four very popular libraries for data handling.
EDA is considered a basic and one of the most important steps in data science. It helps us planning advance data analytics by revealing the nature of feature and target variables and their interrelationships.
Every advanced application of data science like machine learning, deep learning or artificial intelligence requires a thorough knowledge of the variables you have in your data. Without a good exploratory data analysis, you can not have that sufficient information about the variables.
In this article, we will discuss four very popular and useful libraries of Python namely Pandas, NumPy, Matplotlib and Seaborn. The first two are to handle arrays and matrices whereas the last two are for creating beautiful plots.
I have created this exploratory data analysis code file in Jupyter notebook with a common data file name and use it anytime a new data set is to be analyzed. The variable names just need to be changed. It saves my considerable time and I am thorough with all the variables with a good enough idea for further data science tasks.
NB: Being a non-native English speaker, I always take extra care to proofread my articles with Grammarly. It is the best grammar and spellchecker available online. Read here my review of using Grammarly for more than two years.
Pandas and NumPy provide us with data structures for data handling. Pandas has two main data structures called series and data frame as data container. Series contains data of mixed type in one-dimensional array whereas data frame is a two-dimensional array having columns with the same kind of data so, it can be considered as a dictionary of series.
Lets first import all the required libraries.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
The data set used here is the very popular Titanic data set from Kaggle (https://www.kaggle.com/c/titanic/data). It contains the details of the passengers travelled in the ship and evidenced the disaster. The data frame contains 12 variables in total which are as below.
The target variable here is the ‘Survived‘ which contains the information if the passenger survived the disaster or not. It is a binary variable having ‘1’ representing the passenger has survived and ‘0’ indicating the passenger has not survived.
The other variables are all feature variables. Among the feature variables, ‘Pclass‘ contains the class information which has three classes like Upper, Middle and Lower; ‘SibSp‘ contains the number of passengers in a relationship in terms of sibling or spouse, the variable ‘Parch‘ also displays the number of relationships in terms of ‘parent‘ or ‘child‘, the ‘Embarked‘ variable displays the name of the particular port of embarkation, all other variables carry information as the variable names suggest.
Here is the shape of the data set.
df.shape
(891, 12)
It shows that the data set has 891 rows and 12 columns.
Basic information
The info() function displays some more basic information like the variable names, their variable type and if they have null values or not.
The head() function prints few starting rows of the data set for our understanding.
df.head()
Sample of the data set
Summary statistics
The describe() function prints some basic statistics of the data in hand.
df.describe()
Summary statistics
To get some idea about the non-numeric variables in the data set
df.describe(include=[bool,object])
Boolean, object count
Inspecting any particular variable more closely
df.Fare.mean()
32.2042079685746
What if we take any categorical variable for inspection? Lets consider the target variable “Survived” here. It is a binary variable as I have mentioned before.
df[df['Survived']==1].mean()
PassengerId 444.368421
Survived 1.000000
Pclass 1.950292
Age 28.343690
SibSp 0.473684
Parch 0.464912
Fare 48.395408
dtype: float64
So, it reveals important information that those who survived the disaster has an average age of 28 and they have spent on an average $48 for the fare.
Let’s find out some more critical information using logical operators. Like if we want to know what is the maximum age of a survivor travelling in Class I.
Similarly, the youngest passenger from class I was 71 years old. Such queries can retrive very interesting information.
Suppose we want to inspect the passenger details whose names start with ‘A’. Here I have used the ‘lambda‘ function for the purpose. It makes the task very easy.
Another very useful function is ‘replace()‘ from Pandas. It allows us to replace a particular value of any variable with our desired character. For example, if we want to replace the ‘Pclass‘ variable values 1,2 and 3 with ‘Class I’, ‘Class II’ and ‘Class III’ respectively then we can use the following piece of code.
This is another important function frequently used to get summary statistics. Below is an example of its application to group the variables ‘Fare‘ and ‘Age‘ with respect to the target variable ‘Survived‘.
Contingency table or cross-tabulation is a very popular technique to create a table for multivariate data set in order to display the frequency distribution of variables corresponding to other variables. Here we will use the crosstab() function of Pandas to perform the task
pd.crosstab(df['Survived'], df['Pclass'])
Contingency table
So, you can see how quickly we can get the passenger class wise tally of passenger’s survival and death count through a contingency table.
Pivot table
The ‘Pivot_table()‘ function does the job by providing a summary of some variables corresponding to any particular variable. Below is an example of how we get the mean ‘Fare‘ and ‘Age’ of all passengers either survived or died.
We can sort the data set with respect to any of the variables. For example below we have sort the data set with respect to the variable “Fare“. The parameter “ascending=False” specifies that the table will be arranged in descending order with respect to variable ‘Fare‘.
df.sort_values(by=["Fare"], ascending=False)
Sorted with respect to ‘Fare’
Visualization using different plots
Visualization is the most important part in case of performing exploratory data analysis. It reveals many interesting pattern among the variables which otherwise tough to recognise using numerals.
Here we will use two very capable python libraries called matplotlib and seaborn to create different plots and charts.
Check for missing values in the data set
A heat map created using the seaborn library is helpful to find out missing values easily. This is quite useful as if the data frame is a big one and missing values are few, locating them is not always easy. In this case, such a heatmap is quite helpful to find out missing values.
import seaborn as sns
plt.rcParams['figure.dpi'] = 100# the dpi can be set to enhance the resolution of the image
# Congiguring retina format
%config InlineBackend.figure_format = 'retina'
sns.heatmap(df.isnull(), cmap='viridis',yticklabels=False)
Heatmap to locate missing values
So, we can notice from here that out of total 12 variables, the variables “Age” and “Cabin” only have the missing values. We have used the ‘retina’ format of seaborn library to make the plot more sharp and legible.
Also, see the code to create these two plots as subplots and how the figure size has been mentioned. You can create separate plots without specifying all these details and see the effect. These specifications will help you adjust the plots and make them more legible.
Plotting the variable “Survived” to compare the dead and alive passengers of Titanic with a bar chart
sns.countplot(x=df.Survived)
Bar plot for variable ‘Survived’
The above plot displays how many people survived out of all passengers. Again if we want these comparison according to the sex of the passengers, then we should incorporate another variable in the chart.
sns.countplot(df.Survived,hue=df.Sex)
Bar plot showing the survival according to passengers’ sex
The above plot reveals an important information regarding the survival of the passengers. From the plot we have drawn before it was evident that the death was higher than the number of people survived the disaster.
Now if we group this survival according to the sex, it further reveals that the number of male passengers survived the accident was much more than that of female passengers. Also, the death count for female passengers was also higher than male passengers.
Lets inspect the same information with a contingency table
Contingency table for count of passengers survived according to their sex
Again if we want to categorize the plot of survival of the passenger depending on the class of the passengers, then we can have the information about how many passengers of a particular class have survived.
Bar plot with two categorical variables
There were three classes which have been represented as class 1,2 and 3. Let’s prepare a count plot with passenger class as the subcategory in case of survival of the passengers
sns.countplot(df.Survived, hue=df.Pclass)
Count plot for passenger class wise survival
The above plot clearly shows that the death toll was much higher in case of passenger of class 3 and class 1 passengers had the highest survival. Passengers of class 2 have almost equal no. of death and survival rate.
The highest no. of passengers were in class 3 and so the death toll too. We can see the below count plot where it is evident that class 3 has a much higher number of passengers compared to the other classes.
Again we can check the exact figure of passenger survival according to the passenger class with a contingency table too as below.
Below a seaborn distribution plot has been created with simple “distplot()” function all other parameters are set to the default one. By default, it calculates the standard normal values to display its distribution pattern.
sns.distplot(df.Age, color='red')
Distribution plot-1
If we want the original ‘Age’values to be displayed, we need to set the ‘kde’ as ‘False’.
Box plot and violin plots are also very good visualization method to determint the distribution of any variable. See the application of these two plots for the variable ‘Fare‘ below,
The whiskers in the boxplot above, display the interval of the point scatter which is (Q1−1.5⋅IQR, Q3+1.5⋅IQR) where Q1 is the first quartile, Q3 is the third quartile and IQR is the Inter Quartile range i.e. the difference between 1st and 3rd quartile.
The black dots represent outliers which are beyond the normal scatter marked by the whiskers. On the other hand the violin plot, the kernel density estimate has been displayed on both sides.
Creating a boxplot to inspect the distribution
Below is a boxplot created to see the distribution of different passenger class with respect to the fare and as expected the highest fare class is the first class. Another boxplot has been created with the same ‘Pclass‘ variable against the “Age” variable.
These two boxplots side by side let us understand the relation between passengers’ age group and their choice of classes. We can clearly see that senior passengers are more prone to spend higher and travel in higher classes.
Here we will inspect the relationship between the numerical variables using the correlation coefficient. Although the data set is not ideal to do this correlation study as it lacks numerical variables having a meaningful interrelation.
But for the sake of complete EDA steps, we will perform this correlation study with the numerical variables we have in our hand. We will produce a heatmap to display the correlation with different colour shades.
Scatter plots are very handy in displaying the relationship between two numeric variables. The scatter() function of matplotlib library does this very quick to give us the first-hand idea about the variables.
Below is a scatterplot created between the ‘Fare‘ and ‘Age‘ variables. Here the two variables are taken as Cartesian coordinates in the 2D space. But even 3D scatterplots are also possible.
plt.scatter(df['Age'], df['Fare'])
plt.title("Age Vs Fare")
plt.xlabel('Age')
plt.ylabel('Fare')
Scatter plot
Creating a scatterplot matrix
If we want a glimpse of the joint distribution and one to one scatterplots among all combinations of the variables, a scatterplot matrix can be a good solution. The pairplot() function of the seaborn library does the job for us.
Below is an example with the scatter_var variable we created before with all the numerical variables in the data set.
sns.pairplot(df[scatter_var])
Scatter plot matrix
See the above scatterplot matrix, the diagonal plots are the distribution plot for the corresponding variables while the rest of the scatterplots are for each pair of the variables.
To conclude with I will discuss a very handy and useful function from Pandas. Pandas profiling can create a summary from the data set in a jiffy.
Pandas profiling
First of all you need to install the library using the pip command.
pip install pandas-profiling
It will take some time to install all its module. Once it gets installed then to execute it run the below line of codes. The ProfileReport() function creates the EDA_report and finally an interactive HTML file is created for the user.
from pandas_profiling import ProfileReport
EDA_report = ProfileReport(df)
EDA_report.to_file(output_file='EDA.html')
It is a very helpful process to perform exploratory data analysis specially for those who does not very familiar to coding and statistical analysis and just want some basic idea about his data. The interactive report allows them to dig further to get a particular information.
Disadvantage
The main demerit of pandas profiler is it takes too much time to generate report when the data set is huge one. And many a time the practical real world data set has thousands of records. If you through the entire data set to the profiler you might get fustrated.
In this situation ideally you should use only a part of the data and generate the report. The random sample part from the whole dat set may also help you to have some idea about the variables of interest.
Conclusion
Exploratory data analysis is the key to know your data. Any data science task starts with data exploration. So, you need to be good at exploratory data analysis and it needs a lot of practice.
Although there are a lot of tools which can prepare a summary report from the data at once. Here I have also discussed Pandas profiling function which does all data exploration on your behalf. But my experience is, these are not that effective and may result in some misleading result in case the data is not filtered properly.
If you do the exploration by hand step by step, you may need to devote some more time, but in this way you become more familiar to the data. You get a good grasp about the variables which helps you in advance data science applications.
So, that’s all about exploratory data analysis using four popular python libraries. I have discussed every function with example which are generally required to explore any data set. Please let me know how you find this article and if I have missed anything here. I will certainly improve it according to your suggestions.
This article discussed two very easy fixes for this problem faced by almost all Jupyter notebook users while doing data science projects. I have faced this issue myself while working folder of Jupyter notebook, the most preferred IDE of data scientists.
Although at the start it did not seem a big problem, as you start using Jupyter on a daily basis, you want it should start from your directory of choice. It helps you being organized, all your data science files at one place.
While I searched the internet thoroughly and got many suggestions, very few of them were really helpful. And it took quite a lot of my time to figure out the process which is really helpful. I thought to write it down as a blog so that in future I don’t have to waste time again to fix the issue and so my readers.
So, without any further ado, lets jump to the solutions…
NB: Being a non-native English speaker, I always take extra care to proofread my articles with Grammarly. It is the best grammar and spellchecker available online. Read here my review of using Grammarly for more than two years.
The first and the quickest solution is to run your Jupyter notebook right from the Anaconda PowerShell. You need to just change the directory to the desired one there and run Jupyter notebook. It is that simple. See the below image
Running the jupyter notebook with anaconda powershell
Here you can see that the default working folder of Jupyter notebook was c:\user\Dibyendu as in the PowerShell. I have changed the directory to E: and simply run the command jupyter notebook. Consequently, PowerShell has run the Jupyter notebook with the start folder as mentioned.
This is very effective and changes the start folder for jupyter notebook very easily. But the problem is that this change is temporary and you have to go through this process every time you open the notebook.
To fix this problem one solution can be to create a batch file with these commands and just run this batch file while you need to work in jupyter notebook.
Creating shortcut with target as the working folder of Jupyter notebook
This solution is my favourite and I personally follow this procedure. Here the steps are explained with screenshots from my system.
You need to first locate the jupyter notebook app in your computer by right clicking the application in your menu as shown in the below image.
Jupyter notebook app in my start menu
Now navigate to the file location and select the application file like the below image. Copy the file in your desktop or any location you want a shortcut of the application.
Location the jupyter notebook application in your computer
Now right-click the application and go to the shortcut tab. The target file you can see here is mentioned as “%USERPROFILE%”, which is indeed the default installation folder for jupyter notebook. That’s why it is the default start folder for the notebook.
Property dialog for Jupyter notebook app
Now you need to replace the “%USERPROFILE%” part with the exact location of your desired directory.
Changed target folder
In the above image you can see that I have replaced the “%USERPROFILE%” with the data science folder which contains all of my data science projects. Now just click Apply and then OK. Now to open jupyter notebook click the shortcut and jupyter will open with your mentioned directory as the start folder as in the below image.
jupyter notebook with the data science folder as the start folder
So, the problem is solved. You can use this trick and create multiple shortcuts with different folders as the start folder of jupyter notebook.
Web scraping, also known as web harvesting or screen scraping or web data extraction is a way of collecting a large amount of data from the internet. In data science, especially in machine learning, the accuracy of the model is largely dependent on the amount of data you have. A large amount of data helps to train the model and make it more perfect.
Across all business domains, data plays a crucial role to decide strategies, competitor price monitoring, consumer sentiment analysis, extracting financial statements etc. Be it a small business owner or business tycoons, the market data and analytics is something they always need to keep a tab to survive the cutthroat competition. Every single decision they take towards business expansion is driven by the data.
Web scraped data collected from diverse sources enables us to get real-time analytics i.e. data gets analyzed right after the data is available. There are instances where a delayed data analysis report has no use. For example, stock price data analysis needs to be real-time for trading. Customer Relationship Management (CRM) is also an example of real-time data analytics.
Source of data
So, what is the source of such a large amount of data? Obviously the internet. There are a lot of open-source data and also web sites catering to specialised data. Generally, we visit such sites one at a time and search for the information we look for. We put our query and the required information is fetched from the server.
This process is okay until and unless we need data for a data science project. The amount of data required for a satisfactory machine learning model is huge and a single website can not cater much.
Data science projects involve projects like Natural Language Processing (NLP), Image recognition etc. which has revolutionalized artificial intelligence application towards solving our day to day needs and even critical path-breaking scientific achievements. In these cases, web scraping is the most favourite and frequently used tool by data scientists.
Web scraping in data science can be defined as the construction of a computer programme which automatically downloads, parse, organize data from the internet (source: https://www.kdnuggets.com).
Points to remember before you go for web scraping in data science
Now before you go for data scraping from any website, you must double-check if the site allows web scaping. If the website is open-source or categorically mentions that it caters data for private use then no issue. Otherwise, you can check for the robots.txt file of the site. Sometimes the site clearly mentions if they have issues with web scaping from their site.
For example, see the robots.txt file of Facebook. You can check it navigating to the link https://www.facebook.com/robots.txt. There you can see a few lines at the very beginning of the file which categorically mentions “collection of data on Facebook through automated means is prohibited unless you have express written permission from Facebook”.
Robots.txt file of Facebook.com
So, checking the robots.txt is also an effective way of checking if data scraping is at all allowed by the website you want to scrape.
Web scraping can be accomplished both using web APIs or tools like BeautifulSoup. BeautifulSoup is a class specially made for web scraping and available with bs4 package. It is a very helpful package and saves programmers a lot of time. It helps to collect data from HTML and XML files.
Let’s try a very basic web scraping code using the BeautifulSoup class of bs4 package of Python.
A practical example of data scraping
Lets take a practical example where we can scrap a data table from a webpage. We will take the URL of this page itself and try to scrape the below table. It is an imaginary example table containing the age, height and weight data of 20 random persons.
Name
Gender
Age
Height
Weight
Ramesh
Male
18
5.6
59
Dinesh
Male
23
5.0
55
Sam
Male
22
5.5
54
Dipak
Male
15
4.5
49
Rahul
Male
18
5.9
60
Rohit
Male
20
6.0
69
Debesh
Male
25
6.1
70
Deb
Male
21
5.9
56
Debarati
Female
29
5.4
54
Dipankar
Male
22
5.7
56
Smita
Female
25
5.5
60
Dilip
Male
30
4.9
49
Amit
Male
14
4.8
43
Mukesh
Male
26
5.1
50
Aasha
Female
27
4.7
51
Dibakar
Male
22
5.3
55
Manoj
Male
33
6.2
75
Vinod
Male
27
5.2
54
Jyoti
Female
22
5.9
65
An example table for data scraping
Suppose this table we want to use in our data science project. So, how we can bring the data in a usable format. This table is just an example, and usually, you will find tables with thousands of rows and the number of web pages with such tables. But the process of scraping data will be the same.
Let’s try to scrape this small table using the bs4 library of Python. It stands for BeautifulSoup version 4. The bs class defines the basic interface called by tree builders.
Importing required libraries
The two special libraries we will need here are BeautifulSoup and requests for scraping information and grabbing the URL content.
# Importing required libraries
import requests
from bs4 import BeautifulSoup as bs # defines the basic interface called by the tree builders
In this section we are importing other basic important libraries like pandas, numpy, matplotlib, seaborn etc.
# Importing other important libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Accessing the web pages and scraping the content
To open this particular page here I used openurl function of the library urllib through its request module. And then passing the html content with the BeautifulSoup function. Don’t bother about the ‘lxml‘ part right now. You will get to know about it later on.
# Opening the particular url using openurl function
from urllib.request import urlopen
url='https://dibyendudeb.com/what-is-web-scraping-and-why-it-is-so-important-in-data-science/'
html= urlopen(url)
soup=bs(html,'lxml')
Now the BeautifulSoup has a very useful function called find_all to find all the HTML content with a particular tag. You can explore these tags from the inspect option when you do right-click on any part of a web page.
See below the images to understand the way you can identify particular HTML tag of any specific web page content.
Inspecting the HTML tag of a web page
The records of this table are with tr and td tags. Which clearly indicates that we need to apply the find_all function with these two tags.
The specific HTML content
So let’s apply find_all to get all the values with these two tags from this web page and then create string objects with them. The resultant content we have stored here in a list.
Creating list of web scraped content
# to print all rows in a table
records=soup.find_all('tr')
# creating list with the text
text_list=[]
for row in records:
row_store=row.find_all('td')
text_store=str(row_store) # creating a string object from the given object
onlytext=bs(text_store,'lxml').get_text() # using BeautifulSoup method to collect the text as a list using get_text() function
text_list.append(onlytext)
In the next step, we need to create a data frame from this list to make the data ready for further analysis. Print the data frame to see the records of the table within the HTML tags we mentioned in the code.
But this data need to split to create separate records according to the comma-separated values. The following line of codes creates a proper shaped data structure with multiple columns.
Some more refinement here. You can notice some unwanted braces are present with the records. The following code will fix these issues.
# Removing the opening bracket from the column 0
df1[0] = df1[0].str.strip('[')
# Removing the closing bracket from the column 9
df1[4] = df1[4].str.strip(']')
df1.head(10)
Creating table header
The table has some digits as indices which need to be corrected. We need the first row values as the index values. Let’s do this change. The following few sections first separate the first row in a data frame and then concatenate them to create the final data frame with desired index values step by step.
# Storing the table headers in a variable
headers = soup.find_all('strong')
# Using BeautifulSoup again to arrange the header tags
header_list = []# creating a list of the header values
col_headers = str(headers)
header_only = bs(col_headers, "lxml").get_text()
header_list.append(header_only)
print(header_list)
After the above step, we now have an almost complete table with us. Though need some more refinement, let’s start with the first step. We need the indices as the header of the table. So, we are here renaming the columns of the data frame.
# Assigning the first row as table header
df4=df4.rename(columns=df4.iloc[0])
df4.head(10)
The web scraped data frame with new indices
You can see that the table header here has got replicated as the first record in the table, so we need to correct this problem. Lets drop the first repeated row from the data frame.
# Droping the repeated row from the data frame
df5 = df4.drop(df4.index[0])
df5.head()
The data frame view with header
So, as we have almost the final table now lets explore the basic information about the data in our hand.
df5.info()
df5.shape
Basic information about the data frame
Check for missing value
Although the table we have on this web page does not have any missing value, still to have a check and eliminating any row with missing value is a good practice. Here the dropna function does the trick for us.
# Eliminating rows with any missing value
df5 = df5.dropna(axis=0, how='any')
df5.head()
The data frame eliminating records with any missing value
If you print the columns separately, you can notice some unwanted space and braces are there with the column names. Let’s get rid of them and we are done with refining the data frame. The blank spaces in the column names are clear when we print them.
df5.columns
White spaces in the column names
These white spaces may cause problem when we refer them in the analysis process. So, we need to remove these spaces with the help of following code.
# Some more data refinement to make the dataset more perfect
df5.rename(columns={'[Name': 'Name'},inplace=True)
df5.rename(columns={' Weight]': 'Weight'},inplace=True)
df5.rename(columns={' Height': 'Height'},inplace=True)
df5.rename(columns={' Age': 'Age'},inplace=True)
df5.rename(columns={' Gender': 'Gender'},inplace=True)
print(df5.head())
So, here is the final table with the required information.
The final web scraped data in the data frame
Exploring the web scraped data
Here we will explore the basic statistics about the data. The data has two main variables “Weight” and “Height” lets get their description.
Histogram is also a good data exploration technique describing distribution of any variable. We can check if the data is normal or with some deviation.
#histogram
sns.distplot(df5['Height']);
Histogram of the variable “Height”
Relationship between the two main variables. We will plot a scatter diagram between the variables height and weight to see how they are correlated.
# Relationship between height and weight using a scatterplot technique
df5.plot.scatter(x='Height', y='Weight',ylim=(0.800000))
Thus we have completed web scraping of a table from a web page. The technique demonstrated above is applicable to all similar cases of data scraping whatever be the size of data. The data gets stored in python data frame and can be used for any kind of analysis.
Web scraping in data science from multiple web pages
Now a more complex and rather practical example of web scraping. Many times we see that the particular information we look for are scattered through more than one pages. In this case, some additional skill is required for data scraping from these pages.
Here we will take such an example from this website itself and try to scrape the titles of all the articles written. This is only one parameter that we want to collect but the information is spread through multiple pages.
Taking one parameter will keep the code less complex and easy to understand. But it is equally effective as the process of scraping data of one parameter and multiple parameters is the same.
The index page with URL https://dibyendudeb.com has a total of five pages containing the list of all the articles the website contains. So, we will navigate through all these pages, grab the article titles in a for loop and scrape the titles using BeautifulSoup method.
Importing libraries
To start with the coding the first steps are as usual importing the required libraries. Except for the regular libraries like pandas, NumPy, matplotlib and seaborn we need to import the specialized libraries for web scraping like BeautifulSoup and requests for grabbing the URL of web pages.
# Importing required libraries
from bs4 import BeautifulSoup as bs # defines the basic interface called by the tree builders
from requests import get
# Importing other important libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Use of BeautifulSoup for web scraping in data science
Here we will try the main scraping part. The most important task we need to do here is to identify the particular HTML content tag. This is a little experience-based skill. The more you scan the HTML content of web pages more you become comfortable to identify them.
As we have mentioned before, we want to store the article titles only. So our goal is to identify the particular HTML tag which wraps the title of an article. Let’s take a look at the home page of this website https://dibyendudeb.com. Select any of the article titles, right-click and select inspect from the option. You will get a view as below.
HTML content of particular section of a web page
Here you can see the exact HTML part of the selected web page gets highlighted. It makes our task very easy to identify the particular HTML tag we need to find from the web page. Let’s scan the HTML part more closely to understand the structure of it.
The HTML section of the code we are interested
Scanning the HTML code for web scraping
The above image presents the nested HTML code with the title section. You can here identify the particular division class containing the title of the article. So, we now know which HTML tag and the class unique tag we need to find from the scraped HTML content.
Now the below line of code will grab the particular URL and stores all the required information from all the five pages in a raw form. We will scan the whole part of this code line by line and understand functions of a particular piece of code.
# Opening the particular url using openurl function
from urllib.request import urlopen
titles=[]
pages = np.arange(1, 5, 1)
for page in pages:
#read and open url to scrape
page = "https://dibyendudeb.com/page/" + str(page)
html= urlopen(page)
soup=bs(html, 'html.parser')
topics = soup.find_all('div', attrs={'class': 'obfx-grid-col-content'})
for container in topics:
title=container.h1.a.text
titles.append(title)
Creating an empty list
The titles=[] is an empty list is declared first to store the titles. Then we have created a variable called pages to hold the page numbers which are 1,2,3,4 and 5. The np.arrange takes the first value, last value and the interval we want between them.
Use of for loop
After that, we enter into a for loop which iterates through the pages to get the content from all the web pages. Now when we are storing the URLs into the page variable, we need to pass a variable which changes with the change of web pages.
Scanning multiple webpages
If we check the URL of different pages of the web site, you can notice the page no. gets associated with the URL. For example, the URL of page 2 is https://dibyendudeb.com/page/2/. Likewise, page 3 and 4 get the page no. with the URL.
Accessing the URL
So, we need to simply concatenate the page no. with the URL within the for a loop. Which has been done with the code "https://dibyendudeb.com/page/" + str(page). We need to convert the page no. into a string as it will be a part of the URL.
html= urlopen(page): With this piece of code the page contents have been stored in the variable html variable. Next, soup=bs(html, 'html.parser') the BeautifulSoup function parses the HTML content in a variable called soup.
As we now we have the parsed HTML content of all the pages, we need to find only the article titles. The process of finding the article title I have already explained above.
Use of find_all and nested for loop to populate the list
topics = soup.find_all('div', attrs={'class': 'obfx-grid-col-content'}). Here in this code, the HTML code with required attributes have been stored in the variable named topics
for container in topics: title=container.h1.a.text titles.append(title) : This piece of code is another nested for loop part which scans through the content of “topics” and stores the exact title in the variable “title“. And finally, the title gets appended in the “titles" list.
With this part, we have completed the scraping part. What remains is just refining the data and creating data frame from the list. Lets first check what we have scraped from the website. We are going to print the length and the content of the variable titles.
print(len(titles))
print(titles)
The scraped content
The length is 40. Which is exactly the number of the total articles the website contains. So, we are satisfied that the code has done what we expected from it. The content also confirms it. Here are a few starting lines from the output of the print command.
40 ['\n\t\t\t\t\tDeploy machine learning models: things you should know\t\t\t\t', '\n\t\t\t\t\tHow to create your first machine learning project: a comprehensive guide\t\t\t\t', '\n\t\t\t\t\tData exploration is now super easy with D-tale\t\t\t\t', '\n\t\t\t\t\tHow to set up your deep learning workstation: the most comprehensive guide\t\t\t\t', '\n\t\t\t\t\tWhy Ubuntu is the best for Deep Learning Framework?\t\t\t\t', '\n\t\t\t\t\tAn introduction to Keras: the most popular Deep Learning framework\t\t\t\t', '\n\t\t\t\t\tA detailed discussion on tensors, why it is so important in deep learning?\t\t\t\t', '\n\t\t\t\t\t ............................................................................................................... More lines
Creating data frame from the list
Web scraping in data science is incomplete unless we have a data frame of the content. So, here we create a data frame from the list titles. We give the index name of the column as “Blog title”. Some basic information and the first 10 rows of the data frame are displayed.
The web scraped data is now in a data frame. But there are some unwanted spaces with character. Let’s clean it to have more refined data set.
# Replacing unwanted characters with a blank at the end of column 9
df1["Blog title"] = df1["Blog title"].str.replace('\n\t\t\t\t\t', '')
df1["Blog title"] = df1["Blog title"].str.replace('\t\t\t\t', '')
df1.head(10)
So, here is the final data set containing titles of all the articles the web site contains. The first 10 article titles are displayed here. Congratulations!!! you have successfully completed a whole exercise of web scraping in data science. Below is a look of the final data frame.
Web scraping in data science
The below piece of code creates a comma separated file to store the data frame. You can open it in excel for further analysis.
df1.to_csv('titles.csv')
Final words
So, we have thoroughly learned all the techniques of web scraping in data science. The article presents the basic logic behind scraping any kind of data from a particular web page and also from multiple pages.
These two are the most prevalent scenarios when we want to web scrape for data science. I have used the same web site for both the example but the logic is same for any kind of source. Personally I have found these logic very useful and applied for my analysis quite a lot.
The article will help you in many ways to collect your data of interest and take an informed decision. As the use of the internet grows astronomically, the businesses become more dependent on data. This era where data is the ultimate power and you need to use it wisely to survive the competition. And in this context, web scraping of data can give you a significant competitive advantage.
So, I am hopeful that the article will also help you in your tasks for web scraping in data science. It is very useful as well as an interesting trick. Don’t just read it, copy the code and run in your machine to see the result. Apply the same with any other source and see how it works.
Finally let me know if you find the article helpful. Post if you have any questions in the comment. I will love to answer them 🙂
To deploy machine learning(ML) models means to take a machine learning model from development to production. You have built an ML model, validated and tested its performance. But what its use if it is not utilised to solve real-world problems? Deploying a model means making an ML model production-ready. Here in this blog, we will discuss the steps of this process.
The deployment process takes a model out from the laboratory or from the data scientist’s desk and makes its appropriate use. There are lots of model across all sectors of industry and most of them are never in use. Every time develop any model the obvious question I have faced from my peers is “how do you make people use the models you develop?”
Why do we need to deploy a model?
Actually, I think this is the primary question that should appear in the mind of data scientists even before model building. Maurits Kaptein of Tilburg University has rightly pointed out in his article that ”the majority of the models trained in … never make it to practice”. This is so true. In his article, he illustrated how brilliant models are developed in medical research die silently in the notebook only as they never reach other health care professionals to reap the benefit.
This is where the importance of model deployment lies. In the agricultural term, we sometimes coin this process as “Lab to Land” process. That means what technologies scientists develop in the lab should reach the land for practical implementation.
Now in case of ML model development, the life cycle is different from that of software development. In the case of software development, the requirement analysis of the client is an integral part. But the data scientists are less concern about the model’s implementation process and highly focused to build a satisfactory model with high precision.
Lets first discuss a machine learning model’s life cycle to understand why the deployment process is so important.
Model development life cycle
A machine learning model development process has several steps. And the model needs to keep always updated. The model needs to be trained with fresh and relevant data in order to keep it updated. See the below diagram of a machine learning model life cycle. Notice that the last stage fo development of an ML model involves iterative steps of updating the model with new data.
Machine learning model development life cycle
A model once developed and forgot remains no longer relevant to the rapidly changing scenario. Target -feature relationship changes, features evolve also new features get added. So it is a continuous and dynamic process. In an ideal condition, the model development and production team should remain in continuous touch to maintain the updation process.
This is also known as end-to-end model data science workflow. It includes data preparation, exploratory data analysis, data visualization, model training, testing, prediction and performance testing. Once a model performance is satisfactory the model is ready for deployment.
What is model deployment?
Suppose a data scientist has developed a model in his computer using an interactive notebook. Now he wants to encapsulate it in such a way that its prediction or analyzing capability can straightway be utilised by the end-users. To do that the data scientist can adopt a number of ways to deploy his/her project. Let’s discuss them one by one.
Creating libraries and packages
This refers to the process to encapsulate your code in a library. The programming language can be anyone of your choice. An ML model created in R, Python, Scala, etc., a library encapsulates all the functionalities of the ML model. It is ready to use for any other data scientists on their own data.
A library or package created to deploy any data science model needs to be updated at regular intervals. For this purpose, it also has the feature to maintain its version in the repository. This feature helps you to keep track of versions and allows the flexibility to use any particular library version.
Hosted or static notebook
Using Jupyter notebook is the most popular way of creating ML models. It is an interactive IDE which allows you to write code and also data visualization, writing texts all at one place.
Jupyter notebook
When you finished with the model development part, you can use the same notebook to host either in Github or Jupyter nbviewer or Anaconda cloud either as a static notebook or as a rendered notebook service. You need to just take care of the basics of deployment. Other nitty-gritty like security, scalability, compatibility issues are taken care of by the hosting service itself.
You can give version numbers to your notebook so that as it gets updated with new data, tracking the version change is possible. This form of deployment is very attractive for any business analysts ready with an updated business report.
Also, it enables end-users with no access to any kind of resources either data or computing to take the benefit of data exploration and visualization. On the other hand, the trade-off is being static report it limits the interaction and poor real-time experience.
Use of REST APIs
This is another way of deploying your machine learning models. In this case, a data scientist once done with model building task deploy it as REST (Representational State Transfer) API. And then other production engineers provide the required layers of visualization, dashboards or web applications. Then the end-users make use of the machine learning model from the REST API endpoints.
Deploy machine learning models using REST API
An ideal example of use of such APIs is ML models built in Python language. Python has the full and exhaustive set of modules which can take care of all the steps starting from data handling, model building to model deployment.
It has data handling libraries like Pandas, NumPy, model building libraries like Scikit-Learn, Tensor, Keras etc. And then a vast range of frameworks like Django, Flask etc. to deploy the model built. So learning a single language can make you self sufficient from building a model to its deployment.
Interactive applications
This is also a popular form to deploy machine learning models. It provides the endusers an easy interactive interface to explore, analyze, try any of the ML algorithms and to export the data for further analysis.
Interactive applications does have a server side component. Thus it is not static like hosted or static notebooks. It allows its users to interact with the data and a real time data handling experience.
For example, Bokeh application is such a powerful interactive application. Users can play with the data with the number of functionalities provided in the interface like sliders, drop-down menus, text fields etc.
Dashboards
It is a very popular form of production technique where the user can perform exploratory analysis and understand the deployed project. Here at a time a large number of users can take part to explore the result.
Jupyter notebook is as of now the most preferred way to deploy ML projects as dashboards. Like its interactive notebook, the dashboard has also components for interactively designing the report lay-outs. You can control it to make grid-like or report-like formats.
Issues in deploying machine learning models
So a model needs to get deployed as an interactive application. But many a time it has been observed that the deployment part takes months together to become fully functional. And the problem is that after such a gap the ML model developed gets obsolete. The data it is trained with needs to be updated as well as the training process.
It becomes more of a problem as the data scientist handovers the model to the engineers involved in the deployment. So changes in the model require again involving the data scientists which are not always possible. Even in case, it has been deployed already, the model needs to update time to time. So, the development team and production team need to work in unison.
The gravity of the problem can be easily understood if we consider a practical case of application of Machine Learning models. Lets take the example where credit card companies uses predictive modeling technique to detect fraudulent credit card transactions.
Suppose we have developed an ML model which predicts the probability of a credit card transaction as a fraudulent transaction. Now the model needs to deliver the result the moment credit card transaction happens in realtime.
If the model takes time longer than 5 minutes then what is the use of such a model? The credit card company needs to make a decision the moment a fraud transaction is taking place and flag it. Prediction accuracy is also of utmost importance. If it predicts a fraud with an accuracy of less than 50%, then it is no way more efficient than tossing a coin.
Serverless deployment
So what is the solution? How can be a model kept always updated? A model which is based on old data and not accurate has no industrial value. So, serverless deployment can be a good solution to overcome the issues mentioned above. Serverless deployment is like the next level of cloud computing.
All the intricacies of the deployment process are taken care of by the deployment platform. The platform completely separates the server and application part in case of the serverless deployment process. Thus, data scientists can pay full attention to the development of efficient machine learning models.
Here is a very good article on the serverless deployment of data science model. To apply the process successfully you need to have some knowledge of cloud computing, cloud function and obviously machine learning.
Types to deploy machine learning models
Suppose a product manager of any company has found out a solution for customer centric problem in his business and it involves the use of machine learning. So, he contacts data scientists to develop the machine learning algorithm part of the total production process.
But a machine learning model life cycle and a software development life cycle differes. Most of the cases the developers of the model have no clue how the model can ultimately be taken to production stage. So the product manager needs to clearly state his requirement to the whole team to meet the end goal.
Now the deployment of a machine learning model majorly depends on the end-user type. How quickly the client needs the prediction result and the interface. Depending on these criteria the product manager needs to decide how the final product should look like. Let’s take a few examples of such real-world applications of machine learning deployment cases.
Example 1: ML model result gets stored in database only
This is a situation where the client has some knowledge of SQL and can fetch the required data from the database. So here if the production manager can only store the ML output in a designated database and his task is complete.
Use of lead scoring model can be a good example of such a situation. Lead scoring is generally a technique followed by marketing and sales companies. They are interested to know the market interest in their products. There are different parameters which indicate market readiness of their product.
A lead scoring model analyses all these parameters like the no. of visits of the product page, lead generation, checking the price, no. of clicks etc. to predict the lead score. Finally the lead score gets stored in a database and revised on daily basis or as per the client’s requirement.
Example 2: the data needs to be displayed on the interface
Here the situation is the marketing executive does not know SQL and unable to fetch the required data from the database. In this case, the product manager needs to instruct his engineers to go one step further than the earlier one. They now need to display the data through Customer Relationship Management (CRM) platform. Which needs to Extract-Transform-Load operations to integrate the data from different sources.
Example3: interactive interface
In this case the user interface is interactive. The ML model result operates on the end-user’s input and returns required result. This can be web application or mobile apps. For example, several decision support systems are there where users input their particular condition and the application guide them with proper recommendations.
Mobile apps like Plantix (see the below clip from the developers) helps users to know the plant disease accurately. The user needs to click pictures of the disease affected part of the plant and the image recognition algorithm of the app determines the disease from its already stored image libraries. Additionally, this app helps the user with proper guidance to get rid of the problem.
Conclusion
Any good Machine Learning model if not deployed has not practical use. And this is the most common case across the industry. Efficient models are developed but they never see the day light and remains forever in the notebook. This is mainly because lack of harmony between the development phase and production phase and some technical constrains like:
Portability of the model
The data science models developed in a local computer works fine until it changes the place of execution. The local computer environment is ideally set for model execution and the data. So to make it deployable either the new data has to reach to the model or the model has to reach the data. From a portability point of view, the latter option is more feasible.
Data refinement
During model development the data scientists procure data from multiple sources and preprocess them. Thus the raw data takes good shape and in ideal form to feed the ML algorithms. But as soon as it goes to production phase, it has to deal with the client’s raw data without any filtering and processing. So model’s robustness is a concern for their deployment.
The latency period
While the model is in the development phase, it has to deal with huge data set. Model training, validation, testing and finally prediction, quite obvious the time takes in this process is long enough. But while in production the prediction process may take a few example case and deliver the prediction. So the expected latency is far less. Also, the industry’s requirement is a real-time prediction most of the time.
So, a data scientist needs to take all the above factors into account while model development. There are several approaches like using containers, using good memory management practice, server less deployment which help to overcome the technical constrains to a great extent. However ML model development and deployment is a continuous process and refinement, training of the model goes on even after a successful deployment.
I have tried to present all the aspects while deploying machine learning models. It is a vase topic and a single article is not enough to discuss it in detail. Still I have covered most of the important factors briefly here so that you can have a basic idea at one place.
In coming articles I will try to cover details with in-depth articles taking one aspects at a time. Please let me know your opinion about the article, any queries regarding the topic by commenting below. Also mention if there is any particular topic you want to read next.
This article contains a brief discussion on python functions. In any programming language, be it Python, R, Scala or anything else, functions play a very important role. Data science projects require some repetitive tasks to perform every time to filter the raw data and while data preprocessing. In this case, functions are the best friend of a data scientist. They save them from doing the same task every time by simply calling the relevant function.
Functions, both inbuilt and user-defined are a very basic yet critical component in any programming language and python is no exception. And here is a brief idea about them, so that you can start using the benefit they provide.
Why use Python for data science? Python is the most favourite language among data enthusiasts. One of the reason is Python is very easy to understand and code with compare to any other language.
Besides, there are lots of libraries from third parties which make data science tasks a lot easier. Libraries like Pandas, NumPy, Scikit-Learn, Matplotlib, seaborn all contain numerous modules catering almost all kind of function you wish to perform in data science. Libraries like Tensorflow, Keras are specially designed for deep learning applications.
If you are a beginner or you have some basic ideas about coding in other programming languages, this article will help you get into python functions as well as creating a new one. I will discuss here some important Python functions, writing your own functions for repetitive tasks, handling Pandas data structure with easy examples.
Like other objects of python like integer, string and other data types function are also considered as the first-class citizen in python. They can be dynamically created, destroyed, defined in other functions, passed as arguments in other functions, returned as values etc.
Particularly if we consider the field of data science, we need to perform several mathematical operations and pass on calculated values further. So, the role of python functions is very crucial in data science to perform any particular repetitive calculation, as nested function, to be used as argument of another function etc.
So without much ado, lets jump into details of it and some really interesting use of function with examples.
Use of Python functions for data science
Using functions is of utmost importance not only in Python but in any programming language. Be it inbuilt function or user-defined functions you should have a clear idea how to use them. Functions are very powerful to make your coding well structured and increases its usability.
Some functions are there in Python, we just need to call these built in functions to perform the assigned tasks. Most of the basic tasks we need to do frequently in data operations are well covered in these functions. To start with I will discuss some of these important built in python functions.
Built in python functions
Let’s start with some important inbuilt functions of Python. These are already included and makes your coding experience much smoother. The only condition is you have to aware of them and frequently use them. The first function we will discuss is help().
So take help()
Python functions take care of most of the tasks we want to perform through coding. But the common question comes into any beginner’s mind is how will he/she know about all these functions?. The answer is to take help.
The help function is there in Python to tell you every detail about any functions you need to know to use them. You just need to mention the function with help. See the example below.
# Using help
help(print)
Here I want to know about the print function, so I mentioned it within the help. Now see the help describes everything you need to know to apply the function. The function header with optional arguments you need to pass, their role. It also contains a brief description of the function, what it does in English.
Interestingly you can know all about the help() function using the help function itself :). It is great to see the output. Please type to see it yourself.
# Using help() for help
help(help)
Again here help has produced all necessary details about itself. It says that help() function is actually a wrapper around pydoc.help that provides a helpful message for the user when he types “help” in the Python interactive prompt.
List() function
A list is a collection of objects of same or different data types. It has very frequent use in storing data and later used for operations in data science. See the below code to create a list with different data types.
# Defining the list item
list_example=["Python", 10, [1,2], {4,5,6}]
# Printing the data type
print(type(list_example))
# Printing the list
print(list_example)
# Using append function to add items
list_example.append(["new item added"])
print(list_example)
Above code creates a list with a string, a digit, array and set. The type function to print the type of data. And at last, the append() function used to add an extra item in the list. Let’s see the output.
So, the data type is list. All the list items are printed. And an item is appended in the list with append() function. Note this function as it is very handy while performing data analysis. You can also create a complete list from scratch only using the append() function, see the below example.
sorted() function
This is also an important function we need frequently while doing numeric computation. For example a very basic use of sort() is while calculating the median of a sample data. To find out the median, we need to sort the data first. By default the function sort() arrange the data in ascending order, but you can do the reverse also by using the reverse argument. See the example below.
# Example of sorted function
list_new=[5,2,1,6,7,4,9]
# Sorting and printing the list
print("Sorting in an ascending order:",sorted(list_new))
# Soritng the list in descending order and printing
print("Sorting in an descending order:",sorted(list_new,reverse=True))
And the output of the above code is as below:
Use of function sorted()
round() function
This function is useful to give you numbers with desired decimal places. The required decimal place is to be passed as an argument. These decimal number has some unique properties. See the below example and try to guess what will be the output, it is really interesting.
# Example of round() function
print(round(37234.154))
print(round(37234.154,2))
print(round(37234.154,1))
print(round(37234.154,-2))
print(round(37234.154,-3))
Can you guess the output. See the second argument can be negative also!. Lets see the output and then explain what the function does to a number.
When the round() function has no argument, it simply discards any decimal digits. It keeps up to two decimals if the argument is 2 and one decimal when it is 1. Now when the second argument is -2 or -3, it simply returns the closest integer with multiple of 100 or 1000.
If you are surprised where on the earth such a feature is useful; then let me tell you that there are some occasions like mentioning a big amount (money, distance, population etc) where we don’t need an exact figure, rather a rounded close number can do the job. In such cases to make the figure easier to remember, round() function with a negative argument is used.
Now there are a lot more in-built functions, we will touch them in other articles. Here as an example I have covered few of them. Lets move on to the next section of user-defined function. It gives you freedom to create your own functions.
User defined functions
After inbuilt functions, here we will learn about user defined functions. If you are learning Python as your first programming language, then I should tell you that functions in any programming language are the most effective as well as an interesting part.
Any coder’s expertise depends on how skilled he is in creating functions to automate the repetitive tasks. Instead of writing code for the same tasks again and again a skilled programmer writes some function for those tasks and just call them when the need arises.
Below is an example how can you create a function of adding two numbers.
# An example of user defined function
def add (x,y):
''' This is a function to add two numbers'''
total=x+y
print("The sum of x and y is:", total)
The above is an example of creating a function which will add two numbers and then print the output. Let’s call the function to add two numbers and see the result.
I have called the function, passed two digits as arguments and the user-defined function printed the result of adding the numbers. Now anytime I will need to add two numbers I can just call this function instead of writing those few lines again and again.
Now if we want to use help for this function, what will help return? Lets see
See help() function has returned the text I have put within three quoted strings. It is called the docstring. A docstring allows us to describe the use of the function. It is very helpful as complex programmes require a lot of user-defined functions. The function name should indicate its use but many a time it may not enough. In such cases, a brief docstring is very helpful to quickly remind you about the function.
Optional arguments in user-defined function
Sometimes providing an optional argument with the default argument save us writing additional lines. See the following example:
Can you guess the output of the following function calls? Just for fun try without seeing the below output. While trying notice that once the function has been called with an optional argument.
Here is the output.
See for the first call of the function, it has printed the default argument. But when we passed “python” as an optional argument, it has overridden the default argument. Again in the third case without any optional argument, the default gets printed. You should try any other combinations come in your mind, it is complete fun and also your concept will get clear.
Nested functions
Nested functions are when you define functions inside another function. This is also one of the very important python basics for data science. Below is an example of a very simple nested function. Try it yourself to check the output.
# Example of nested functions
def outer_function(msg):
# This is the outer function
def inner_function():
print(msg)
# Calling the inner function
inner_function()
# Calling the outer function
outer_function("Hello world")
Functions passed as argument of another function
Functions can also be passed as an argument of another function. It may sound a little confusing at first. But it is really a very powerful property among the python basics utilities for data science. First, take an example to discuss it. See the below piece of code to check the property.
# Calling functions in a function
def add(x):
return 5+x
def call(fn, arg):
return (fn(arg))
def call_twice(fn, arg):
return(fn (fn(arg)))
print(
call(add, 5),
call_twice(add, 5),
sep="\n"
)
Again you try to understand the logic and guess the output. Copy the code and make little changes to see the change or error it produces. The output I got from this code as below.
Did you guess it right? See here we have created three functions namely add(), call() and call_twice(). And then passed the add() function into other two functions. The call() function has returned the add function with argument 5 so the output is 10.
In a similar fashion, the call_twice() function has returned 15 due to the fact that it has a return statement with a nested function and argument combination. I know it is confusing to some extent. This is because the logic has not come from a purpose. When you will create such functions to really solve some problem the concept will get clear. So, do some practice with the code given here.
This article is to help you to start with your first machine learning project. Machine learning projects are very important if you are serious about your career as a data scientist. You need to build your profile with a number of machine learning projects. These projects are evidence of your proficiency and skill in this field.
The projects are not necessarily only complex problems. They can be very basic with simple problems. What is important is to complete them. Ideally, in the beginning, you should take a small project and finish it. It will boost your confidence as you have successfully completed it as well as you will get to learn many new things.
So, to start with I have also selected a very basic problem which is the classification of Iris data set. You can compare it with the very basic “Hello world” program that every programmer writes as a beginner. The data set is small that’s why easy to load in your computer; consists of a few no. of features only so implementation of any ML algorithm is easier.
I have used here Google Colab to execute the Python code. You can try any IDE you generally use. Feel free to copy the code given here and execute them. The first step is to use the existing code without any error. Afterwards, make little changes to see how the output gets affected or gives errors. This is the most effective way to know a new language as well as its application in Machine Learning.
The steps for first machine learning project
So, without much ado, lets jump to the project. You first need to chalk out the steps of implementing the project.
Importing the python libraries
Importing and loading the data set
Exploring the data set to have a preliminary idea about the variables
Identifying the target and feature variables and the independent-dependent relationship between them
Creating training and testing data set
Model building and fitting
Testing the data set
Checking model performance with comparison metrics
This is an ideal sequence how you should proceed with the project. As you gain experience you will not have to remember them. Being the first machine learning project I felt it necessary to mention them for further reference.
Importing the required libraries
# Importing required libraries
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import numpy as np
About the data
The data is collected from UCI machine learning repository, Iris data set and created by Dr R. A. Fisher. It contains three Iris species viz. “Setosa”, “Versicolor” and “Virginica” and four flower feature namely petal length, petal width, sepal length and sepal width in cm. Each of the species represents a class and has 50 samples each in the data set. So the Iris data has total 150 samples.
This is the most popular and basic data used in pattern recognition to date. The data source is UCI machine learning repository and it is a little different from the same Iris data set found in R.
The following line of code will load the data set in your working environment.
# Loading the data set
dataset = load_iris()
The following code will generate a detail description of the data set.
# Printing some data features
dataset.DESCR
Description of Iris data
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
Checking the data type
We can check the data type before proceeding for analytical steps. Use the following code for checking the data type:
# Checking the data type
print(type(dataset))
Now here is a problem with the data type. Check the output below, it says it is a sklearn data.
Data type
Although the most common data type we are used to is Pnadas dataframe. And also the target and feature are stored here separately. You can print them separately using the following lines.
# Printing the components of Iris data
print(dataset.target_names)
print(dataset.target)
print(dataset.feature_names)
See the print output below. The target variables are the three Iris species “Setosa”, “Versicolor” and “Virginica” which are coded as 0,1 and 2 respectively. And the features are also stored separately.
Components of Iris data set
And the feature values are stored separately as data. Here is first few rows of the data.
# Printing the feature data
print(dataset.data)
Converting the data type
For the ease of further modelling process, we need to convert the data type from sklearn to the most common Pandas data type. And we also need to concatenate the separate data and target with column names as feature_names and target. The np.c_ function concatenates the data set.
# Converting scikit learn dataset to a pandas dataframe
import pandas as pd
df = pd.DataFrame(data= np.c_[dataset['data'], dataset['target']],columns= dataset['feature_names'] + ['target'])
df.head()
See below few lines of the combined dataframe. With this new dataframe we are now ready to proceed for the next step.
The new Panda dataframe
Check the shape of the newly created dataframe as I have done below. The output confirms that the dataframe is now complete with 150 samples and 5 columns.
# Printing the shape of the newly created dataframe
print(df.shape)
Creating target and feature variables
Next, we need to create variables storing the dependent and independent variables. Here the target variable Iris species is dependent on the feature_variables so the flower properties i.e. petal width, petal length, sepal length and sepal width are independent variables.
The data set printed above, you can see that the first four columns are independent variables and the last one has the dependent variable. So, in the below line of codes, variable x is to store the values of first four columns and y for the target variable.
# Creating target and feature variables
x=df.iloc[:,0:4].values
y=df.iloc[:,4].values
print(x.shape)
print(y.shape)
The shape of x and y is as below.
Shape of x and y
Splitting the data set
We need to split the data set before applying Machine learning algorithms. The train_test_split() function of sklearn has been used here to do the task. The test data size is set as 20% of the data.
# Splitting the data set into train and test set
x_train, x_test, y_train, y_test=train_test_split(x,y,test_size=0.2,random_state=0)
print(x_train.shape)
print(x_test.shape)
Accordingly, the train data set contains 120 sample data whereas the test data set has 30 sample data.
Application of Decision tree algorithm
So, we have finished with data processing steps and ready to apply the Machine Learning algorithm. I have chosen here a very popular classification algorithm which is Decision Tree algorithm for the first machine learning project.
If this algorithm is new to you, you can refer to this article to learn details about it and how it can be applied with Python. The speciality of this ML algorithm is that its logic is very simple and the process is not black box like most other ML algorithms. Which means that we can see and understand how the decision-making process is going on.
So let’s apply this ML model to the training set of Iris data. The DecisionTreeClassifier() of sklearn is the function here which we have imported in the beginning.
# Application of Decision Tree classification algorithm
dt=DecisionTreeClassifier()
# Fitting the dt model
dt.fit(x_train, y_train)
The model thus applied on the training set. In the below screenshot of my Colab notebook you can see the classifier has several parameters specifying the decision tree formation. At this stage you don’t need to bother about all these specifications. We can discuss each of them and what is their function in another article.
Fitting the Decision Tree Classification model
Prediction using the trained model
To test the model we will first create a new data. As this data has not been used in model building so the prediction will not be biased.
# Creating a new feature set i.e. a new flower properties
x_new = np.array([[4.9, 3.0, 1.4, 0.2]])
# Predicting for the new data using the trained model
prediction = knn.predict(x_new)
print("Prediction:",prediction)
See the prediction result using the trained Decision Tree classifier. It gives the result as 0 which represents the iris species “Setosa”. We have discussed before the Iris species are represented in the data frame with digits 0,1 and 2.
Prediction for the new data
Lets try to predict the result using the test set with 20% of data kept independent while model training. We will also use two metrics suggesting the goodness of fit of the model.
y_pred = dt.predict(x_test)
print("Predictions for the test set:",y_pred)
# Metrics for goodness of fit
print("np.mean: ",np.mean (y_pred == y_test))
print("dt.score:", dt.score(x_test, y_test))
And the output of the above piece of code is as below.
Prediction using the test set
You can see that the testing accuracy score is 1.0!. So, it is indicating a problem. The problem of overfitting. Which is very common with Decision Tree Classification. Overfitting suggests that the model is a too good fit for this particular data set. Which is not desirable. And ideally, we should try other machine learning models to check their performance.
So in this section next we will not take up a single ML algorithm, rather we will take up a bunch of ML algorithms and test their performance side by side to choose the best performing one.
Application of more than one ML models simultaneously
Along with these ML models another segment which I am going to introduce is known as Ensemble models. The specialty of this method is that an ensemble model uses more than one machine learning models at a time to achieve more accurate estimation. See the below figure to understand the process.
An ensemble model
Now there are two kinds of ensemble models which are Bagging and Boosting. I have incorporated both kinds of ensemble models here to compare them with other machine learning algorithms. Here is a brief idea about Bagging and Boosting ensemble techniques.
Bagging
The name is actually Bootstrap Aggregation. It is essentially a random sampling technique with replacement. That means here once a sample unit is selected, it is again replaced back for further future selection. This method works best with algorithms which tend to have higher variance and bias, like decision tree algorithm.
Bagging method runs a different model separately and for the final prediction output aggregates each model’s estimation without any bias to any model.
The other ensemble modelling technique is:
Boosting
As an ensemble learning method, boosting also comprises a number of modelling algorithm for prediction. It associates weight to make a weak learning algorithm stronger and thus improving the prediction. The learning algorithms also learn from each other to boost the overall model performance.
The ensemble models we are going to use here are AdaBoostClassifier(), BaggingClassifier(), ExtraTreesClassifier(), GradientBoostingClassifier() and RandomForestClassifier(). All are from sklearn library.
Importing required libraries
# Importing libraries
from sklearn.model_selection import cross_val_score
from sklearn import ensemble
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns
Application of all the models
Use this following lines of code to build, train and execute all the six models. It also consists of an array with name ml_compare[]. It stores all the comparison matrices calculated here.
# Application of all the ML algorithms at a time
ml = []
ml.append(('LDA', LinearDiscriminantAnalysis())),
ml.append(('DTC', DecisionTreeClassifier())),
ml.append(('GNB', GaussianNB())),
ml.append(('LR', LogisticRegression(solver='liblinear', multi_class='ovr'))),
ml.append(('SVM', SVC(gamma='auto'))),
ml.append(('KNN', KNeighborsClassifier())),
ml.append(("Ensemble_AdaBoost", ensemble.AdaBoostClassifier()))
ml.append(("Ensemble_Bagging", ensemble.BaggingClassifier()))
ml.append(("Ensemble_Extratree", ensemble.ExtraTreesClassifier()))
ml.append(("Ensemble_GradientBoosting", ensemble.GradientBoostingClassifier()))
ml.append(("Ensemble_RandomForest", ensemble.RandomForestClassifier()))
ml_cols=[]
ml_compare=pd.DataFrame(columns=ml_cols)
row_index=0
# Model evaluation
for name, model in ml:
model.fit(x_train,y_train)
predicted=model.predict(x_test)
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
cv_results = cross_val_score(model, x_train, y_train, cv=kfold, scoring='accuracy')
ml_compare.loc[row_index, 'Model used']=name
ml_compare.loc[row_index,"Cross Validation Score" ]=round(cv_results.mean(),4)
ml_compare.loc[row_index,"Cross Value SD" ]=round(cv_results.std(),4)
ml_compare.loc[row_index,'Train Accuracy'] = round(model.score(x_train, y_train), 4)
ml_compare.loc[row_index,"Test accuracy" ]=round(model.score(x_test, y_test),4)
row_index+=1
ml_compare
As all the models get trained and executed with the train set, they are simultaneously tested with the test data. The goodness of fit statistics gets stored in ml_compare[]. So, let’s see now what ml_compare[] tells us. The output is as below.
Comparative table of cross validation score of all the models
Visual comparison of the models
Although from the above table the models can be compared, it is always easier if there is a way to visualize the difference. So, let’s create a bar chart using the cross-validation score. we have calculated above. Use the following line of codes to create the bar chart with the help of matplotlib and seaborn module of sklearn.
# Creating plot to show the train accuracy
plt.subplots(figsize=(13,5))
sns.barplot(x="Model used", y="Train Accuracy",data=ml_compare,palette='hot',edgecolor=sns.color_palette('dark',7))
plt.xticks(rotation=90)
plt.title('Model Train Accuracy Comparison')
plt.show()
As the above code executes, the following bar chart is created showing the cross-validation scores of all the ML algorithms.
The verdict
So, we have classified the Iris data using different types of Machine Learning and ensemble models. And the result shows that they all are more or less accurate in identifying the Iris species correctly. But if still, we need to pick any one of them as the best, then we can do that based on the above comparative table as well as the graph.
For this instance, we have Linear Discriminant and Support Vector Machine performing slightly better than the others. But it can vary depending on the size of data and ML scores do change in different executions. You also check your result, which one you have found best and let me know through comments below.
Conclusion
So, congratulations you have successfully completed your very firs machine learning project with python. You have used a popular and classic data set to apply several machine learning algorithms. The data being a multiclass data set is an ideal example of real world classification problem.
To find out the best performing model, we have applied the six most popular Machine Learning algorithms along with several ensemble models. To start with the model building process, first of all, the data set has been divided into training and testing sets.
The training set is to build and train the model. The test data set is an independent data set kept aside while building the model, to test the model’s performance. This is an empirical process of model validation when independent data collection is not possible. For this project, we have taken an 80:20 ratio for train and test data set.
And at the last a no. of comparison metrics were used to find the model with the highest accuracy. These are essentially the ideal steps of any machine learning project. As it is your first machine learning project experience, so I have showed every step with all details. As you advance in experience you may skip some of them as per your convenience.
So, please let me know your experience with the article. Any problem you faced while executing the code or any other queries post them in the comment section below, I will love to answer them.
This article is to introduce you a really super easy data exploration tool from Python. You have to just install and import this simple module. It gets integrated with any python IDE you are using. And D-tale is ready with all its data exploration features and a very easy user interface.
Data exploration is a very basic yet very important step of data analysis. You need to understand the data the relationship between the variables before you dive deep into advance analysis. Basic data exploration techniques like visual interpretation, calculating the summary statistics, identifying the outliers, mathematical operations on variables etc. are very effective to gain a quick idea about your data.
These data exploration steps are necessary for any data science projects. Even in machine learning and deep learning projects also we filter our data through these data exploration techniques. And they involve writing a few lines of Python code which are usually repetitive in nature.
This is a complete mechanical task and writing reusable code helps a bit. But again you need code manipulation to some extent every time new data set in use. Every time we write “dataset.head()” wishing that had there been a user interface to do these basic tasks, it can be a big time saver.
So here comes D-tale to rescue us. D-tale is actually a lightweight web client developed over the Pandas data structure. It provides an easy user interface to perform several data exploration tasks without the need of writing any code.
What is D-tale?
D-tale is an open-source solution developed by SAS to Python conversion for visualizing your data using Pandas data frame. It encapsulates all the coding for implementing Pandas data structure operations in the backend so that you don’t need to bother about coding the same thing repeatedly.
SAS insight function earlier which eventually transformed into D-tale with a wrapper written in pearl script. D-tale also gets easily integrated with python terminals and ipython notebooks. You just need to install it in Python and then import it.
You can refer this link for further knowledge about this tool. It is from the developers and also contains some useful resources. Here is a good video resource by the developer of D-tale Andrew Schonfeld from FlaskCon 2020.
I am using it for some time and really liked it. It has made some of my regular repetitive data exploration tasks very easy. It saves lots of my time.
Here I will discuss in detail how can it be installed and start to use with screenshots from my computer while I have installed it.
Installation
The installation part is also a breeze. Within seconds you can install it and start to use. Just open your Anaconda Powershell Prompt from windows start. See the image below.
Opening Anaconda Powershell Prompt from start
Now type the following command in Anaconda Powershell Prompt to install the D-tale in your windows.
Below is the screenshot of my computer’s anaconda shell. Both the Conda and Pip command has been executed. As you know that both of these commands function in a similar way. The only difference is pip installs from the Python package index whereas Conda installs packages from Anaconda repository.
Now you are ready to use the D-tale. Open your Jupyter notebook and execute the following codes.
# To import Pandas
import pandas as pd
# To install D-tale
import dtale
Importing D-tale module in Jupyter notebook
Example data set
The example dataset I have used here for demonstration purpose has been downloaded from kaggle.com. The data collected by “National Institute of Diabetes and Digestive and Kidney Diseases” contains vital parameters of diabetes patients belong to Pima Indian heritage.
Here is a glimpse of the first ten rows of the data set. I have imported the data set in CSV format using the usual pd.read_csv() command. And to show the table use dtale.show().
D-tale working pane
The data set has independent variables as several physiological parameters of a diabetes patient. The dependent variable is if the patient is suffering from diabetes or not. Here the dependent column contains binary variable 1 indicating the person is suffering from diabetes and 0 he is not a patient of diabetes.
Data exploration with D-tale
Now you have the Jupyter notebook displaying the data. And you can click the arrow button on the top left-hand corner to open all the data manipulation tools. See the below image the left pan has several options like describe, build column, correlations, charts etc.
Data exploration tools in D-tale
Descriptive statistics for variables
This is to describe variables showing some descriptive or summary statistics. It does the same task as df.describe() of pandas does. D-tale enables you to get the same result without writing any code, just click the “describe” from the left panel.
In the below image you can show the descriptive statistics of the variable “Pregnancies” has been displayed along with a box-whisker plot. Select any other variable from the left menu and the summary statistics of that particular variable will be displayed.
Describing a variable
Calculation of correlation among the variables
Here is an example of calculating the correlations among the variables. You can see that just on clicking the correlation D-tale has created a beautiful correlation table among all the variables. The depth of colours is very useful to indicate the correlated variables on a glimpse. Like here the dark shade indicated higher correlation.
Correlations between the variables
Preparing charts
Chart creation is a very basic yet very useful data exploration technique. Using D-tale you can create different types of charts like Bar, Line, Scatter, Pie, Heatmap etc. D-tale through its interface has done away writing of several lines of codes. Below is an example of creating a scatter plot with this tool.
As you select the chart option from the left panel of D-tale, a new tab in the browser will open with the following options. You need to select the variables you want to create a scatter plot. There are options to choose X and Y variables. You can also use group by the option to select if there is any categorical variable.
Chart creation wizard
If you desire, also select any of the aggregation options available there, or simply go for the scatter option above. A scatter plot between the two variables will be displayed. Below is the scatter plot with all the options for your reference.
Sections of a chart created in D-tale
The scatter plot contains some tool options as shown in the above image. These tools help you to further dig into the plot’s details. You can investigate any particular point of interest with options like box select or lasso select, change axes setting, to see the data on hover etc.
Other very helpful options to use the chart created here are available as shown in the figure. Like option to pop up the chart in another tab and compare to the another, a link just copy and share, exporting the chart in static HTML which can be attached with e-mail, data export in CSV and finally allows you to copy the Python code to make further customization.
Highlighting the outliers
Another very good and useful feature of D-tale is to highlight the variable wise outliers in a single click. See the below image.
Highlighting the outliers
Creating a pie chart
Here is an example of a Pie chart created with D-tale. Pie chart is also a very popular chart format to show proportional distribution of different components. Creating pie chart follows the same simple process. Just choose pie chart and then select variables you want to display.
Pie chart
Bar plot
Another popular chart format is bar plot. It reveals many important properties of the variables and relation between them. For example here I have created a bar plot between the mean blood pressure against age of different individual. It is an very effective way to know how the blood pressure varies with the age of person. Which is otherwise not easily identifiable from the raw data.
Creating the bar plot is the same and very easy. Here also different aggregation options available. For example I have chosen mean to display the blood pressure along the Y axis.
Creating bar plot
Code export
It is a very useful option D-tale provides. You can get the code for the particular data exploration technique used by you. Now you can make any desired change or simply understand how to write a standard code for learning purpose.
Here is the code snippet below used for creating the bar plot above.
Code export window
Conclusion
This article presents a very helpful data exploration tool which can make your regular data analysis task much easier and quicker. It is a light application and uses Pandas data manipulation libraries underneath.
Its simple and neat user interface gets easily integrated with any IDE you use. Data analysts need a quick idea about the data in hand so that they can plant their advance analytical tasks. So, D-tale can be a tool of choice for them saving considerable time required for writing regular repetitive lines of code.
Wish the article will be helpful. I tried to provide as much information as possible so that you can straightway install and apply it. Do share your experience, how do you find it, is it helpful? Let me know your opinion, any further queries or doubt by commenting below.