
In this article, we will discuss how deep learning training is conducted for problems like speech recognition, image recognition etc. You will have a basic idea about the training algorithm and how it adjusts the weight to reduce the error. A brief discussion will follow on different components of the training process of a deep learning algorithm.
Deep learning actually a very old concept of Machine Learning but it took a long time to gain popularity. Around 2010 it came to prominence and found many uses in fields like near human-level skills in image recognition, speech recognition, improved machine translation, digital assistants like Siri in apple, google know in android applications, Amazon’s Alexa etc.
In case you have sufficient data to train the neural network and high capacity GPU then deep learning can be a good choice for its high accuracy. Higher GPU capacity enhances the model performance.
For problems like speech recognition, the data volume is naturally lesser than image recognition. Data transfer from CPU to GPU plays a significant factor in determining learning efficiency in such smaller problems like speech recognition. But data parameter reduction can not be a solution for problems involving high volume data like image recognition.
Example of Deep learning training
Page contents
See the following two variables. If we carefully analyse, we can identify that they are related and the relationship between them is Y=2X-1.

Human intelligence can identify it by some trial and error methods as long as it is simple like the present one. Deep learning also follows the same principle for identifying the relationship. This process is called learning.
It applies some random values called weights at first to get the output. Initially, the output is much different than the expected one. So, the learning process goes on adjusting the weights and minimize the difference between the estimated and expected output. Thus ultimately it provides an accurate result.
Now if we use these variable combinations in a deep learning network and predict the value of Y corresponding to a value of X=6. It will predict Y= 10.99 instead of 11. As this prediction only on the basis of this sample so, the algorithm is not 100% certain if the prediction is correct.
Role of layers in deep learning training
Deep learning can have tens and thousands of layers theoretically. But when it has a lesser number of layers i.e. only 2-3 layers that learning method often referred to as shallow learning. Let’s consider a deep learning layer has n number of layers. Then if we try to use it for pattern recognition then the consecutive layers will try to identify special features of the pattern.
The more advance the layer, the more advance feature it will identify. In this fashion, after several rounds of optimization of weights, the final layers will recognize the actual pattern. See the below schematic diagram to understand the process.
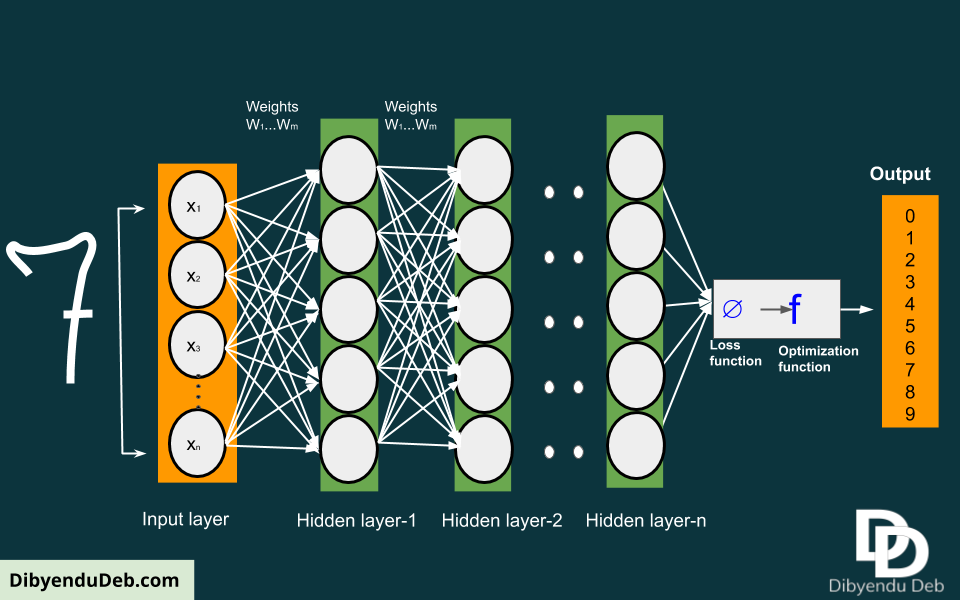
Here what we want the deep learning network to find the digit 7. As you can see we have used n numbers of hidden layers for feature extraction and to identify the character accurately. That’s why this learning process is often referred to as the “multi-stage information distillation process”.
Each hidden layer and input have got some weights, which act as parameters of the layers. After each iteration, we calculate the errors. In the next iteration, the weights again get adjusted to improve the performance further by reducing the error.
This difference between the estimate and expected output is calculated through a loss function. This loss function in a way represents the goodness of fit of the model using the loss score and help to optimize the weights. See the following diagram to understand the process.
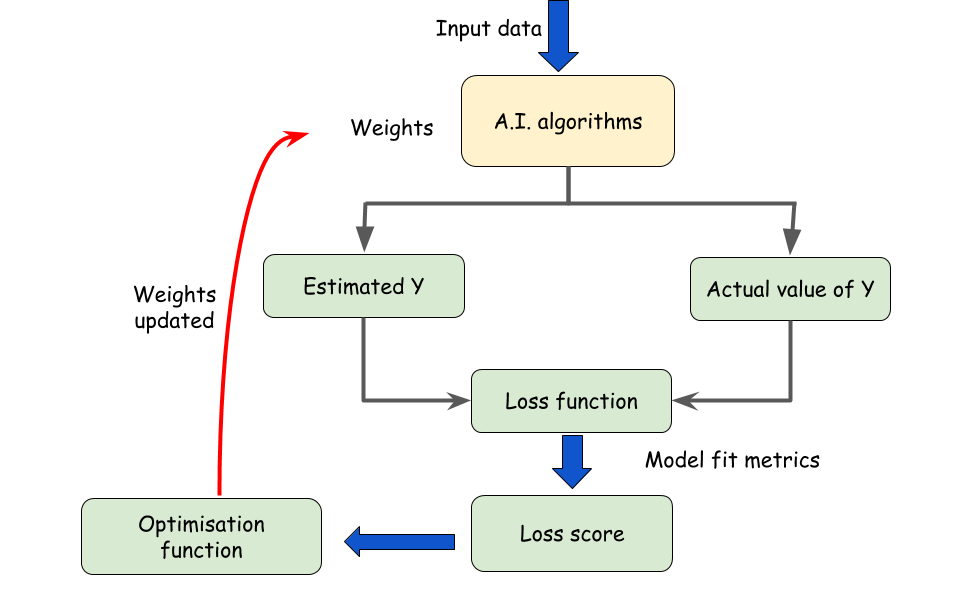
Some key terms used here are like:
Loss function
This is also known as cost function or objective function and used to calculate the deviation of the estimate from the true value. The probabilistic framework used for this function is maximum likelihood. In the case of classification problem, the loss function is a cross-entropy whereas in case of regression problems the Meas Squared Error (MSE) is generally used.
Weight adjustment
The training process starts with some random values of the weights. Calculated the error with these weights and in next cycles again adjust the weights to further reduce the error. This process continues unless a model with satisfactory performance is achieved.
Batch size
If the problem data set is of large size then for training the model small batches of example data is generally used. Such example data with small batch sizes are very handy for an effective estimation of the error gradient. If the complete data set is not very large, then the batch size can be the whole data set.
Learning rate
The rate at which the weights of the layers are adjusted is called the learning rate. The derivative of the error is used for this purpose.
Epochs
This term indicates the no of cycles of weight adjustment needed to achieve a good enough model with satisfactory accuracy. We need to mention the no of epochs we want the training process should go through beforehand while defining the model.
Such a model has the ability to generalize, which means the model trained in such a fashion that the model performs equally well with an independent data set as it has done during the training.
So again I would like to mention that the basic idea of deep learning is very simple and rather empiric than theoretical. But this simple training process when scaled sufficiently can appear like magic.
Backpropagation with Stochastic Gradient Descent
The above figure represents one cycle of the training process through which the weights are adjusted for the next cycle of training. This particular algorithm for training the deep learning network is called the Backpropagation algorithm due to its property of using feedback signal to adjust the weights.
The backpropagation algorithm performs weight optimization through an algorithm known as Stochastic Gradient Descent (SGD). This is the most common algorithm found in almost all neural networks for the optimization process.
Nearly all deep learning is powered by one very important algorithm: Stochastic Gradient Descent (SGD)
Deep Learning, 2016
The iteration of the training process only when a good enough model is found or the model fails to improve or stuck somewhere. Such a training process if often very challenging, time taking and involves complex computations.
The problem with non-convex optimization
Unlike other Machine Learning or regression modelling process, the deep learning training involves non-convex optimization surface. Where in other modelling processes the error has a space shaped like a bowl with a unique solution.
But when the error space is a non-convex one like in case of neural networks, there is neither a unique solution nor any guarantee of global convergence. The error space here comprises of many peaks and valleys with many really good solutions and also with some spurious good estimates of the parameters.
Different steps of training and selecting the best model
A deep learning model performance can be drastically improved if it is trained well. Also scaling up the number of training example and model parameters also play an important role in improving the model fit. Now we will discuss different steps of training a model.
Cleaning and filtering the data
It is a very important step before you jump to train your model. A data set properly cleaned and filtered is even more important than a fancier algorithm. A data set not cleaned properly can result in a misleading conclusion.
You must be aware of the phrase “garbage in, garbage out” popularly known as GIGO in software field; which means that wrong or poor quality input will result in faulty output. So, proper data processing is of utmost importance to work a model effectively.
Data set splitting
A model when built, it needs to be tested with an independent data set, which has not been used in model training. If we don’t have such an independent data set, then we need to split the original data into two parts. One is a training data set (generally 70-80% of the total data) and the remaining part of the data as test data.
Tuning the model
Tuning of the model mainly comprises of estimation of two main parameters of any model viz model parameter and Hyperparameter.
Model parameters
Model parameters are those which define an individual model. These parameres are calculated from the training data itself. For example, the regression coefficients are the model parameters which are calculated from the data set on which the model is trained.
Hyperparameter
These parameters are related to the higher structure of the algorithm and decided before the training process starts. Examples of such parameters are like the no of trees in a random forest, in case of regularized regression strength of the penalty used.
Cross-validation score
This is a model performance metric which helps us to tune the model by calculating a reliable estimate of model performance using the training data. The process is simple. We generally divide the data into 10 groups, use the 9 groups out of these to train the model and the rest one to validate the result.
And this process will be repeated 10 times with different combinations of train and validation sets of data. That’s why it is generally called 10-fold cross-validation. On completion of all these 10 rounds, the performance of the model is determined by averaging the scores.
Selecting the best model
To select the best performing model, we take the help of a few model comparison metrics like Mean Squared Error (MSE) and Mean Absolute Error (MAE) for a regression problem. The lower the values of MSE and MAE the better is the model.
Mean Absolute Error(MAE)
If y is the response variable and yis the estimate then MAE is the error between these npair of variables and calculated with this equation:

MAE is a scale-dependent metric that means it has the same unit as the original variables. So, this is not a very reliable statistic when comparing models applied to different series with different units. It measures the mean of the absolute error between the true and estimated values of the same variable.
Mean Square Error (MSE)
This metric of model comparison is as the name suggests calculate the mean of the squares of the error between true and estimated values. So, the equation is as below:

Whereas in the case of classification problems the common metric that used is Receiver Operating Characteristic (ROC) curve. It is a very important tool to diagnose the performance of MLAs by plotting the true positive rates against the false-positive rates at different threshold levels. The area under ROC curve often called AUROC and it is also a good measure of the predictability of the machine learning algorithms. A higher AUC is an indication of more accurate prediction
Conclusion
At last, a word of caution is to use deep learning wisely for your problem, as it is not suitable for many real-world problems especially when the available data size is not big enough. In fact, deep learning is not the most preferred Machine Learning method used in the industry.
If you are new in the field of Machine Learning, then it is generally a very enticing application of deep learning blindly for any problem. But if there is a different suitable Machine Learning method is available then it is not a wise decision to go for a computation-intensive method like deep learning.
So its a call of the researcher to judge his requirement and available resources to choose the appropriate modelling method. The particular problem, its generic nature and experience in the field play a pivotal role to use the power of deep learning neural network efficiently.
Training a deep learning model is very important to get an accurate result. This article has a detailed discussion on every aspect of this training process. The theoretical background, algorithms used for training and also different steps of it. I hope you will get all your questions related to deep learning training answered here. However please feel free to comment below about the article and also any other questions you want to ask.