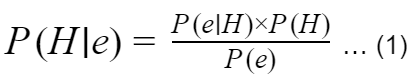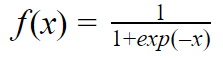In this article, I am going to discuss a very popular deep learning framework in Python called Keras. The modular architecture of Keras makes working with deep learning a very smooth and fast experience. Keras handles all higher-level deep learning modelling part very smoothly in both GPU as well as CPU of your workstation.
So, there is no surprise Keras with TensorFlow is the most popular and widely used deep learning framework. This post will introduce you with this framework so that you feel a little comfortable as you start using it for your deep learning experiments.
As you finish this article you will get some introductory idea about Keras like:
- What is Keras and why it is so popular in deep learning research
- Important features of Keras framework
- The modular architecture of Keras
- The back ends of Keras application like TensorFlow, Theano and Microsoft’s Cognitive Technology or CNTK in short
- A brief comparison between the frameworks
So lets start with the very basic question…
What is Keras?
It is an Open-Source library written in Python to build neural network models. Keras is efficient enough to let us conduct deep learning experiments very fast while being very user friendly, extensible with modular architecture.
Keras was developed by Francois Chollet under the research project ONEIROS (Open Ended Electronic Intelligent Robot Operating System). Francois Chollet, an engineer with Google and also the creator of Xception deep neural network model.
Popularity of Keras as a deep learning framework
Keras is distributed under the MIT permissive licence; which makes it freely available even for commercial use. It can be considered as one of the big reasons for its popularity.
See the image below showing the search volume in thousands in Google trend for some popular deep learning frameworks.

TensorFlow being the default python library for all kind of basic operations is always popular in the machine learning domain. So do the sci-kit learn library, which is very famous for machine learning especially for so many shallow learning algorithms.
But you can see that Keras is also a popular keyword in spite of its very high-end use in neural models. We have to keep in mind that deep learning itself is a very specialized field with very limited use among researchers from specific industries.
Keras was conceptualized for the researchers to conduct deep learning experiments in academia and research setups like NASA, NIH, CERN. The Large Hadron Collider at CERN also used Keras in their search of unknown particles through deep learning.
Besides many famous brands like Google, Uber, Netflix, many startups are also heavily dependent on Keras for their deep learning application in different R&D activities.
The famous machine learning competition website Kaggle has top 5 winning teams using Keras to solve the challenges and the number is steadily increasing.
Important features of Keras
- The same code can be run in both CPU and GPU and compatible with both Python 2.7 or 3.5
- The deployment is very easy with the help of full deployment capabilities of TensorFlow platform.
- Keras models can directly run from browsers by exporting the models into Java script, TensorFlow lite to run on the iOS, android and other devices.
- Be it a convolutional network or recurrent network, Keras can handle both and even a combination of them.
- Keras is popular in scientific research as the implementation of arbitrary research ideas is easy due to the low-level flexibility of Keras while providing high-level convenience to speed up the experimentation cycles.
- Any task related to computer vision or sequence processing is very fast and smooth in Keras framework
- Keras is capable of building any kind of deep learning model. It may be a generative adversarial network or neural Turing machine, a multi-input/output model etc. etc. Keras will efficiently build them
The modular functionality of Keras
Keras is designed to handle only the high-level model building part in the deep learning ecosystem. It lets the well-optimized tensors to handle the basic lower-level programming part. All the basic tensor operations and transformations are the subjects of specialized tensors managed by TensorFlow library of Google.

In this modular approach, the Keras used another two backends which are Theano and Microsofts’ CNTK. These are very popular deep learning execution engines. These are not exclusive to use with Keras. You can switch to any of them anytime if you find if it is better and faster to tackle the particular task.
All these three libraries enable Keras to run in both the CPU as well as GPU.
Here are these three backends in brief.
TensorFlow

This is a deep learning library developed by Google to handle all tensor operations smoothly. Based on TensorFlow 2.0, Keras has the potential to provide an industry-standard framework for building large GPUs.
During 2017 Google decided to provide support to Keras in TensorFlow’s core library. Francois Chollet was of the opinion that Keras is built as an interface to perform high end deep learning model building task and not a fully functional machine learning framework.
TensorFlow allows Keras code to run in CPU by wrapping itself into a low-level library called Eigen.
Eigen
As the tuxfamily.org mentions ” Eigen is a C++ template library for performing linear algebra: matrices, vectors, numerical solvers and related algorithms”.
cuDNN
And when TensorFlow is to run in the GPU, the library that TensorFlow uses to wrap itself is NVIDIA CUDA Deep Neural Network library (cuDNN). It is a “GPU-accelerated library of primitives for deep neural networks” as mentioned at NVDIA developer website.
The cuDNN library provides highly tuned applications for deep learning functions like forward and backward convolution, pooling, normalization, activation layers etc.
Theano

It is also a Python library especially for performing several mathematical operations like matrix manipulation and transformations and has tight integration with NumPy. Theano is developed by MILA lab of the University of Montreal, Quebec, Kanada. It is also capable to run on both CPU and GPU.
Theano is capable of creating symbolic graphs for calculating gradient descent.
CNTK

This is Microsoft’s Cognitive Tool Kit formerly known as Computational Network Toolkit. It is a free tool kit which is easy to use but gives commercial grade performance in training deep learning algorithms.
Soon after google decided to provide support to Keras in TensorFlow’s core library in 2017; Microsoft also decided to include CNTK at the back end of Keras.
CNTK helps to “describe the neural network as a series of computational steps via a directed graph”
Out of these three backends of Keras implementation, TensorFlow is the most frequently used one because of its robustness. It is highly scalable too.
A comparison between the frameworks
To conclude this article I will summarize the features of Keras and where it is different from the other popular frameworks. The popular three frameworks TensorFlow, Keras and theano are compared in the table below.
We already know a basic difference between them. In deep learning execution point of view, Keras is the implementation interface whereas the rest of them act as the back end. But there are some other key differences between them. Let’s discuss them point by point
| Property | Keras | TensorFlow | Theano | CNTK |
| Licence | MIT licence | Apache 2-D | BSD | MIT |
| Developed by | Francois Chollet | Google Brain | University of Montreal, Quebec, Kanada | Microsoft Research |
| Release | 2015 | 2015 | 2007 | 2016 |
| Written in | Python | C++, CUDA, Python | Python | C++ |
| Platforms | Linux, MacOS, Windows | Linux, MacOS, Windows, Android | Cross platform | Linux, MacOS, Windows |
| API | High level API | Low-level API | Low-level API | Low-level API |
| Use | Used in experimentation with deep learning | Popularly used for all kinds of machine learning | Used for multidimensional matrix operations | CUDA support and parallel execution feature |
| Deep learning type | Used for all deep learning algorithms | Supports reinforcement learning and other algorithms | Not very smooth performer in AWS | A deprecated deep learning framework |
| Open MP support | Yes (with Theano as back end) | Yes | Yes | Yes |
| Open CL support | Yes (With Theano, TensorFlow and PaidML as back end) | Yes | Noy yet, work in progress | No |
| Support for reinforcement learning | No | Yes | No | No |
| Performance | Quite fast with Theano and TensorFlow in back end | Optimized for big models, memory requirement may be higher. | Run time and memory competitive and support for multiple GPU. Compile time is more. | Comparable to Theano and TensorFlow |
| Additional features | Support for Android, Multi GPU support | Android support, Multi GPU support, support for distributed windows OS | Multi GPU support | Cross platform support |
Conclusion
This is all four frameworks in a glimpse. Better not take this table to compare between these frameworks as they are not working independently, rather play together to make up for other’s weaknesses. In this way, we got a really powerful Deep Learning execution engine.
So, I hope this article has been able to give you a very introductory idea about Keras as a deep learning framework. This information is just to make you feel comfortable before you take the first step.
As you enter real deep into the deep learning applications, you will automatically find out more interesting facts as well as points presented here will make more sense to you.
If you find this article helpful please let me know through comments below. In case anything I have missed here or there is any question or doubt, any suggestions please put them also in comments. I would like to answer them.