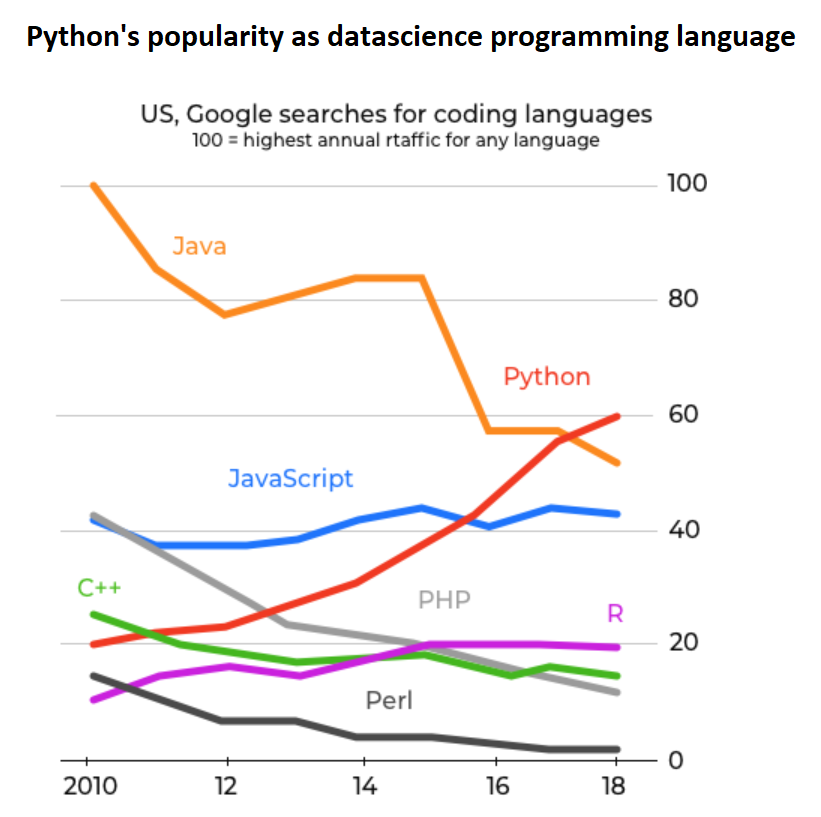
This article presents a thorough discussion on how to perform Exploratory Data Analysis (EDA) to extract meaningful insights from a data set. And to do this I am going to use Python programming language and its four very popular libraries for data handling.
EDA is considered a basic and one of the most important steps in data science. It helps us planning advance data analytics by revealing the nature of feature and target variables and their interrelationships.
Every advanced application of data science like machine learning, deep learning or artificial intelligence requires a thorough knowledge of the variables you have in your data. Without a good exploratory data analysis, you can not have that sufficient information about the variables.
In this article, we will discuss four very popular and useful libraries of Python namely Pandas, NumPy, Matplotlib and Seaborn. The first two are to handle arrays and matrices whereas the last two are for creating beautiful plots.
I have created this exploratory data analysis code file in Jupyter notebook with a common data file name and use it anytime a new data set is to be analyzed. The variable names just need to be changed. It saves my considerable time and I am thorough with all the variables with a good enough idea for further data science tasks.
NB: Being a non-native English speaker, I always take extra care to proofread my articles with Grammarly. It is the best grammar and spellchecker available online. Read here my review of using Grammarly for more than two years.
Data structures for exploratory data analysis
Pandas and NumPy provide us with data structures for data handling. Pandas has two main data structures called series and data frame as data container. Series contains data of mixed type in one-dimensional array whereas data frame is a two-dimensional array having columns with the same kind of data so, it can be considered as a dictionary of series.
Lets first import all the required libraries.
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltThe data set used here is the very popular Titanic data set from Kaggle (https://www.kaggle.com/c/titanic/data). It contains the details of the passengers travelled in the ship and evidenced the disaster. The data frame contains 12 variables in total which are as below.
df=pd.read_csv("Titanic_data.csv")
df.columnsIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')Feature and target variables
The target variable here is the ‘Survived‘ which contains the information if the passenger survived the disaster or not. It is a binary variable having ‘1’ representing the passenger has survived and ‘0’ indicating the passenger has not survived.
The other variables are all feature variables. Among the feature variables, ‘Pclass‘ contains the class information which has three classes like Upper, Middle and Lower; ‘SibSp‘ contains the number of passengers in a relationship in terms of sibling or spouse, the variable ‘Parch‘ also displays the number of relationships in terms of ‘parent‘ or ‘child‘, the ‘Embarked‘ variable displays the name of the particular port of embarkation, all other variables carry information as the variable names suggest.
Here is the shape of the data set.
df.shape(891, 12)
It shows that the data set has 891 rows and 12 columns.
Basic information
The info() function displays some more basic information like the variable names, their variable type and if they have null values or not.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBDisplaying the data set
The head() function prints few starting rows of the data set for our understanding.
df.head()
Summary statistics
The describe() function prints some basic statistics of the data in hand.
df.describe()
To get some idea about the non-numeric variables in the data set
df.describe(include=[bool,object])
Inspecting any particular variable more closely
df.Fare.mean()32.2042079685746What if we take any categorical variable for inspection? Lets consider the target variable “Survived” here. It is a binary variable as I have mentioned before.
df[df['Survived']==1].mean()PassengerId 444.368421
Survived 1.000000
Pclass 1.950292
Age 28.343690
SibSp 0.473684
Parch 0.464912
Fare 48.395408
dtype: float64So, it reveals important information that those who survived the disaster has an average age of 28 and they have spent on an average $48 for the fare.
Let’s find out some more critical information using logical operators. Like if we want to know what is the maximum age of a survivor travelling in Class I.
Use of logical operators
df[(df['Survived'] == 1) & (df['Pclass'] == 1)]['Age'].max()80.0So, the maximum age of a passenger travelling in class I is 80.
df[(df['Survived'] == 0) & (df['Pclass'] == 1)]['Age'].max()71.0Similarly, the youngest passenger from class I was 71 years old. Such queries can retrive very interesting information.
Suppose we want to inspect the passenger details whose names start with ‘A’. Here I have used the ‘lambda‘ function for the purpose. It makes the task very easy.
df[df['Name'].apply(lambda P_name: P_name[0] == 'A')].head()
Another very useful function is ‘replace()‘ from Pandas. It allows us to replace a particular value of any variable with our desired character. For example, if we want to replace the ‘Pclass‘ variable values 1,2 and 3 with ‘Class I’, ‘Class II’ and ‘Class III’ respectively then we can use the following piece of code.
x = {1 : 'Class I', 2 : 'Class II', 3:'Class III'}
df_new=df.replace({'Pclass': x})
df_new.head()
Application of ‘groupby’
This is another important function frequently used to get summary statistics. Below is an example of its application to group the variables ‘Fare‘ and ‘Age‘ with respect to the target variable ‘Survived‘.
var_of_interest = ['Fare', 'Age']
df.groupby(['Survived'])[var_of_interest].agg([np.mean, np.std, np.min, np.max])
Contingency table
Contingency table or cross-tabulation is a very popular technique to create a table for multivariate data set in order to display the frequency distribution of variables corresponding to other variables. Here we will use the crosstab() function of Pandas to perform the task
pd.crosstab(df['Survived'], df['Pclass'])
So, you can see how quickly we can get the passenger class wise tally of passenger’s survival and death count through a contingency table.
Pivot table
The ‘Pivot_table()‘ function does the job by providing a summary of some variables corresponding to any particular variable. Below is an example of how we get the mean ‘Fare‘ and ‘Age’ of all passengers either survived or died.
df.pivot_table(['Fare','Age'],['Survived'],aggfunc='mean')
Sorting the data set
We can sort the data set with respect to any of the variables. For example below we have sort the data set with respect to the variable “Fare“. The parameter “ascending=False” specifies that the table will be arranged in descending order with respect to variable ‘Fare‘.
df.sort_values(by=["Fare"], ascending=False)
Visualization using different plots
Visualization is the most important part in case of performing exploratory data analysis. It reveals many interesting pattern among the variables which otherwise tough to recognise using numerals.
Here we will use two very capable python libraries called matplotlib and seaborn to create different plots and charts.
Check for missing values in the data set
A heat map created using the seaborn library is helpful to find out missing values easily. This is quite useful as if the data frame is a big one and missing values are few, locating them is not always easy. In this case, such a heatmap is quite helpful to find out missing values.
import seaborn as sns
plt.rcParams['figure.dpi'] = 100# the dpi can be set to enhance the resolution of the image
# Congiguring retina format
%config InlineBackend.figure_format = 'retina'
sns.heatmap(df.isnull(), cmap='viridis',yticklabels=False)
So, we can notice from here that out of total 12 variables, the variables “Age” and “Cabin” only have the missing values. We have used the ‘retina’ format of seaborn library to make the plot more sharp and legible.
Also, see the code to create these two plots as subplots and how the figure size has been mentioned. You can create separate plots without specifying all these details and see the effect. These specifications will help you adjust the plots and make them more legible.
Plotting the variable “Survived” to compare the dead and alive passengers of Titanic with a bar chart
sns.countplot(x=df.Survived)
The above plot displays how many people survived out of all passengers. Again if we want these comparison according to the sex of the passengers, then we should incorporate another variable in the chart.
sns.countplot(df.Survived,hue=df.Sex)
The above plot reveals an important information regarding the survival of the passengers. From the plot we have drawn before it was evident that the death was higher than the number of people survived the disaster.
Now if we group this survival according to the sex, it further reveals that the number of male passengers survived the accident was much more than that of female passengers. Also, the death count for female passengers was also higher than male passengers.
Lets inspect the same information with a contingency table
pd.crosstab(df['Survived'], df['Sex'], margins=True)
Again if we want to categorize the plot of survival of the passenger depending on the class of the passengers, then we can have the information about how many passengers of a particular class have survived.
Bar plot with two categorical variables
There were three classes which have been represented as class 1,2 and 3. Let’s prepare a count plot with passenger class as the subcategory in case of survival of the passengers
sns.countplot(df.Survived, hue=df.Pclass)
The above plot clearly shows that the death toll was much higher in case of passenger of class 3 and class 1 passengers had the highest survival. Passengers of class 2 have almost equal no. of death and survival rate.
The highest no. of passengers were in class 3 and so the death toll too. We can see the below count plot where it is evident that class 3 has a much higher number of passengers compared to the other classes.
Again we can check the exact figure of passenger survival according to the passenger class with a contingency table too as below.
pd.crosstab(df['Survived'], df['Pclass'], margins=True)
sns.countplot(df.Pclass)
Creating distribution plot
Below a seaborn distribution plot has been created with simple “distplot()” function all other parameters are set to the default one. By default, it calculates the standard normal values to display its distribution pattern.
sns.distplot(df.Age, color='red')
If we want the original ‘Age’values to be displayed, we need to set the ‘kde’ as ‘False’.

sns.distplot(df['Age'].dropna(),color='darkred',bins=40)
sns.distplot(df.Fare, color='green')
Box plot and violin plot
Box plot and violin plots are also very good visualization method to determint the distribution of any variable. See the application of these two plots for the variable ‘Fare‘ below,
plt.subplot(1,2,1)
sns.boxplot(x=df['Fare'])
plt.subplot(1,2,2)
sns.violinplot(x=df['Fare'],color='red')
The whiskers in the boxplot above, display the interval of the point scatter which is (Q1−1.5⋅IQR, Q3+1.5⋅IQR) where Q1 is the first quartile, Q3 is the third quartile and IQR is the Inter Quartile range i.e. the difference between 1st and 3rd quartile.
The black dots represent outliers which are beyond the normal scatter marked by the whiskers. On the other hand the violin plot, the kernel density estimate has been displayed on both sides.
Creating a boxplot to inspect the distribution
Below is a boxplot created to see the distribution of different passenger class with respect to the fare and as expected the highest fare class is the first class. Another boxplot has been created with the same ‘Pclass‘ variable against the “Age” variable.
These two boxplots side by side let us understand the relation between passengers’ age group and their choice of classes. We can clearly see that senior passengers are more prone to spend higher and travel in higher classes.
plt.subplot(1,2,1)
sns.boxplot(x=df.Pclass,y=df.Fare)
plt.subplot(1,2,2)
sns.boxplot(x=df.Pclass, y=df.Age)
Correlation plot
Here we will inspect the relationship between the numerical variables using the correlation coefficient. Although the data set is not ideal to do this correlation study as it lacks numerical variables having a meaningful interrelation.
But for the sake of complete EDA steps, we will perform this correlation study with the numerical variables we have in our hand. We will produce a heatmap to display the correlation with different colour shades.
# Considering only numerical variables
scatter_var = list(set(df.columns)-set(['Name', 'Survived', 'Ticket','Cabin','Embarked','Sex','SibSp','Parch']))
# Creating heatmap
corr_matrix = df[scatter_var].corr()
sns.heatmap(corr_matrix,annot=True);
Scatter plot
Scatter plots are very handy in displaying the relationship between two numeric variables. The scatter() function of matplotlib library does this very quick to give us the first-hand idea about the variables.
Below is a scatterplot created between the ‘Fare‘ and ‘Age‘ variables. Here the two variables are taken as Cartesian coordinates in the 2D space. But even 3D scatterplots are also possible.
plt.scatter(df['Age'], df['Fare'])
plt.title("Age Vs Fare")
plt.xlabel('Age')
plt.ylabel('Fare')
Creating a scatterplot matrix
If we want a glimpse of the joint distribution and one to one scatterplots among all combinations of the variables, a scatterplot matrix can be a good solution. The pairplot() function of the seaborn library does the job for us.
Below is an example with the scatter_var variable we created before with all the numerical variables in the data set.
sns.pairplot(df[scatter_var])
See the above scatterplot matrix, the diagonal plots are the distribution plot for the corresponding variables while the rest of the scatterplots are for each pair of the variables.
To conclude with I will discuss a very handy and useful function from Pandas. Pandas profiling can create a summary from the data set in a jiffy.
Pandas profiling
First of all you need to install the library using the pip command.
pip install pandas-profilingIt will take some time to install all its module. Once it gets installed then to execute it run the below line of codes. The ProfileReport() function creates the EDA_report and finally an interactive HTML file is created for the user.
from pandas_profiling import ProfileReport
EDA_report = ProfileReport(df)
EDA_report.to_file(output_file='EDA.html')It is a very helpful process to perform exploratory data analysis specially for those who does not very familiar to coding and statistical analysis and just want some basic idea about his data. The interactive report allows them to dig further to get a particular information.
Disadvantage
The main demerit of pandas profiler is it takes too much time to generate report when the data set is huge one. And many a time the practical real world data set has thousands of records. If you through the entire data set to the profiler you might get fustrated.
In this situation ideally you should use only a part of the data and generate the report. The random sample part from the whole dat set may also help you to have some idea about the variables of interest.
Conclusion
Exploratory data analysis is the key to know your data. Any data science task starts with data exploration. So, you need to be good at exploratory data analysis and it needs a lot of practice.
Although there are a lot of tools which can prepare a summary report from the data at once. Here I have also discussed Pandas profiling function which does all data exploration on your behalf. But my experience is, these are not that effective and may result in some misleading result in case the data is not filtered properly.
If you do the exploration by hand step by step, you may need to devote some more time, but in this way you become more familiar to the data. You get a good grasp about the variables which helps you in advance data science applications.
So, that’s all about exploratory data analysis using four popular python libraries. I have discussed every function with example which are generally required to explore any data set. Please let me know how you find this article and if I have missed anything here. I will certainly improve it according to your suggestions.